
질문

황현수
공간 피라미드 풀링은 원본 이미지의 특징이 훼손 되지 않는 큰 장점이 있는데
모든 CNN 구조에 써도 되는지, 한계점은 없는지 궁금합니다.
https://yeomko.tistory.com/14
•
Image Classification이나 Object Detection과 같은 여러 테스크들에 일반적으로 적용할 수 있다는 장점이 있음
한계점
1.
end-to-end 방식이 아니라 학습에 여러 단계가 필요하다. (fine-tuning, SVM training, Bounding Box Regression)
2.
여전히 최종 클래시피케이션은 binary SVM, Region Proposal은 Selective Search를 이용한다. → Region Proposal 과정이 실제 객체 탐색 CNN과 별도로 이루어지기 때문에 선택적 탐색을 쓰면 end to end가 불가능하고 실시간 적용에도 어려움이 있다고 함
3.
fine tuning 시에 SPP를 거치기 이전의 Conv 레이어들을 학습 시키지 못한다. 단지 그 뒤에 Fully Connnected Layer만 학습시킨다. → Fast R-CNN에서 대폭 개선되었다고 함
(fine tuning: 기존에 학습되어져 있는 모델을 기반으로 아키텍쳐를 새로운 목적(나의 이미지 데이터에 맞게)변형하고 이미 학습된 모델 Weights로 부터 학습을 업데이트하는 방법)
박내은
(p. 348) Faster R-CNN
왜 특성 맵이 w*h면 앵커가 w*h*k개인지 모르겠습니다.
https://velog.io/@cha-suyeon/딥러닝-Object-Detection-Anchor-Boxes-NMSNon-Max-Suppression
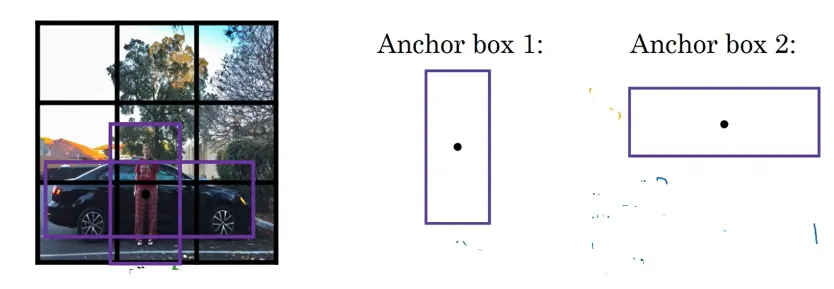

•
RPN은 이미지에 존재하는 객체들의 크기와 비율이 다양하기 때문에 고정된 N x N 크기의 입력만으로 다양한 크기와 비율의 이미지를 수용하기 어려운 단점이 있음
•
이러한 단점을 보완하기 위해 여러 크기와 비율의 레퍼런스 박스 k개를 미리 정의하고 각각의 슬라이딩 윈도우 위치마다 박스 k개를 출력하도록 설계하는데, 이 방식을 앵커(anchor)라고 함
•
즉, 후보 영역 추출 네트워크의 출력 값은 모든 앵커 위치에 대해 각각 객체와 배경을 판단하는 2k개의 분류에 대한 출력과 x, y, w, h 위치 보정 값을 위한 4k개의 회귀 출력을 갖음
•
특성 맵 크기가 w * h라면 하나의 특성 맵에 앵커가 총 w * h * k개 존재함
6장 합성곱 신경망 2
6.2 객체 인식을 위한 신경망

•
객체 인식은 이미지나 영상 내에 있는 개체를 식별하는 컴퓨터 비전 기술
•
즉, 객체 인식이란 이미지나 영상 내에 있는 여러 객체에 대해 각 객체가 무엇인지 분류하는 문제와 그 객체 위치가 어디인지 박스로 나타내는 위치 검출 문제를 다루는 분야
•
객체 인식은 자율 주행 자동차, CCTV, 무인 점포 등에서 활용됨
•
딥러닝을 이용한 객체 인식 알고리즘은 크게 1단계 객체 인식과 2단계 객체 인식으로 나눌 수 있음
◦
1단계 객체 인식
▪
분류와 위치 검출 두 가지를 동시에 행하는 방법
▪
비교적 빠르지만 정확도가 낮음
▪
YOLO계열과 SSD계열 등이 포함
◦
2단계 객체 인식
▪
분류와 위치 검출 두 가지를 순차적으로 행하는 방법
▪
비교적 느리지만 정확도가 높음
▪
CNN을 처음으로 적용시킨 R-CNN 계열이 대표적
R-CNN
•
이전 객체 인식 알고리즘들은 슬라이딩 윈도우 방식(일정한 크기를 가지는 윈도우를 가지고 이미지의 모든 영역을 탐색하며 객체를 검출해내는 방식)
•
비효율적이기 때문에 현재는 선택적 탐색 알고리즘을 적용한 후보 영역(영상/이미지에서 객체가 있을 법한 영역을 의미)을 많이 사용
선택적 탐색 : 객체 인식이나 검출을 위한 가능한 후보 영역을 알아내는 방법으로, 분할 방식을 이용하여 시드를 정하고 그 시드에 대한 완전 탐색을 적용함
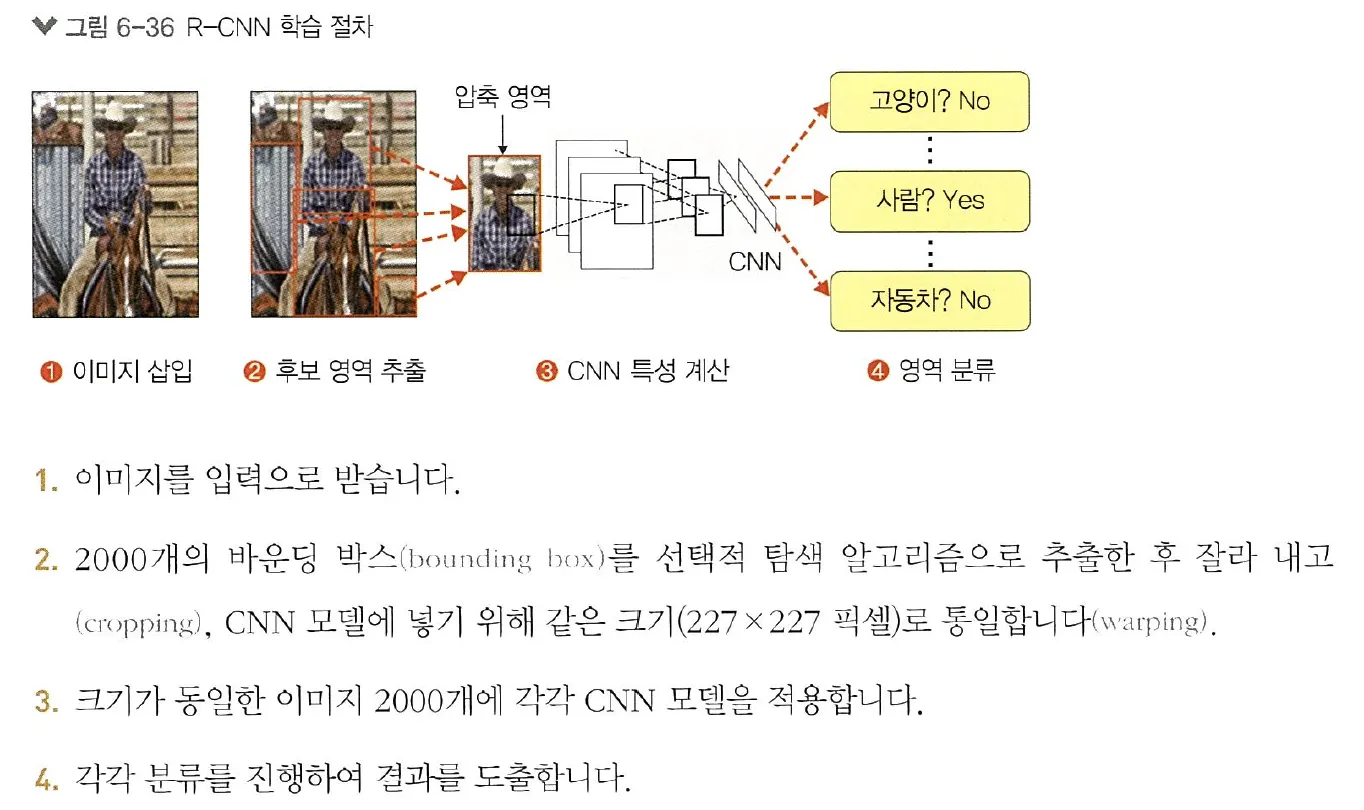
•
R-CNN은 이미지 분류를 수행하는 CNN과 이미지에서 객체가 있을 만한 영역을 제안해 주는 후보 영역 알고리즘을 결합한 알고리즘
•
R-CNN은 성능이 뛰어나기는 하지만 아래와 같은 단점으로 크게 발전하지는 못함 → 해결을 위해 Fast R-CNN이 생김
1.
앞서 언급한 선택적 탐색 세 단계의 복잡한 학습 과정
2.
긴 학습 시간과 대용량 저장 공간
3.
객체 검출 속도 문제
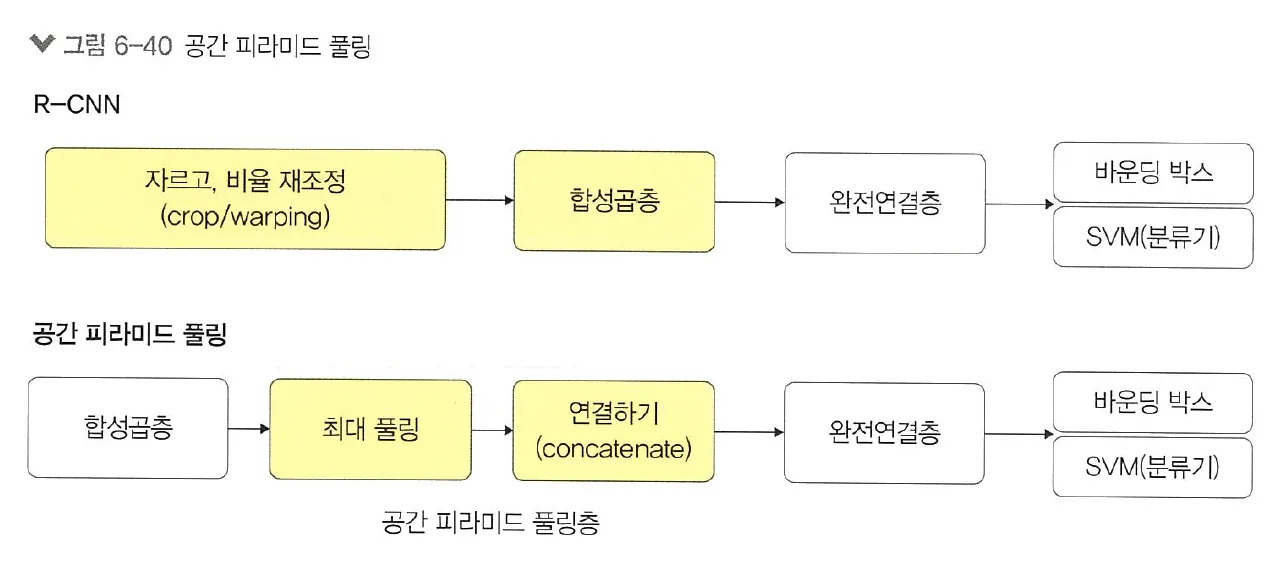
공간 피라미드 풀링(SPP)
•
기존 CNN구조들은 모두 완전연결층을 위해 입력 이미지를 고정해야 했으며 따라서 신경망을 통과시키려면 이미지를 고정된 크기로 자르거나 비율을 조정해야 했음
•
그러나 물체의 일부분이 잘리거나 본래의 생김새와 달라지는 문제점이 있어 이를 해결하고자 공간 피라미드 풀링을 도입함
•
공간 피라미드 풀링 : 입력 이미지의 크기에 관계없이 합성곱층을 통과시키고, 완전연결층에 전달되기 전에 특성 맵들을 동일한 크기로 조절해 주는 풀링층을 적용하는 기법
•
입력 이미지의 크기를 조절하지 않고 합성곱층을 통과시키기 때문에 원본 이미지의 특징이 훼손되지 않는 특성 맵을 얻을 수 있으며, 이미지 분류나 객체 인식 같은 여러 작업에 적용할 수 있다는 장점이 있음
Fast R-CNN
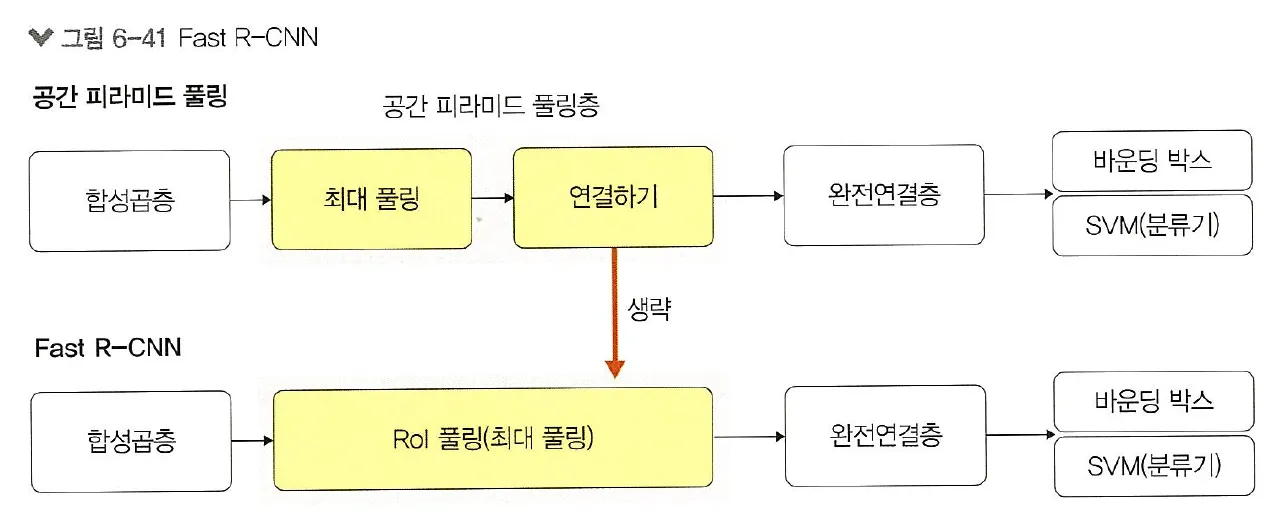
•
R-CNN은 바운딩 박스마다 CNN을 돌리고, 분류를 위한 긴 학습 시간이 문제였으나 Fast R-CNN은 해당 속도 문제를 개선하고자 RoI 풀링을 도입함
RoI 풀링 : 크기가 다른 특성 맵의 영역마다 스트라이드를 다르게 최대 풀링을 적용하여 결괏값 크기를 동일하게 맞추는 방법
•
즉, 선택적 탐색에서 찾은 바운딩 박스 정보가 CNN을 통과하면서 유지되도록 하고 최종 CNN 특성 맵은 풀링을 적용하여 완전연결층을 통과하도록 크기를 조정함 → 바운딩 박스마다 CNN 돌리는 시간 단축 가능
Faster R-CNN
•
더욱 빠른 객체 인식을 수행하기 위한 네트워크로, 기존 Fast R-CNN 속도의 걸림돌이었던 후보 영역 생성을 CNN 내부 네트워크에서 진행할 수 있도록 설계함
•
즉, Faster R-CNN은 기존 Fast R-CNN에 후보 영역 추출 네트워크(RPN)를 추가한 것이 핵심
•
Faster R-CNN에서는 외부의 느린 선택적 탐색(CPU로 계산) 내부의 빠른 RPN(GPU로 계산)을 사용함
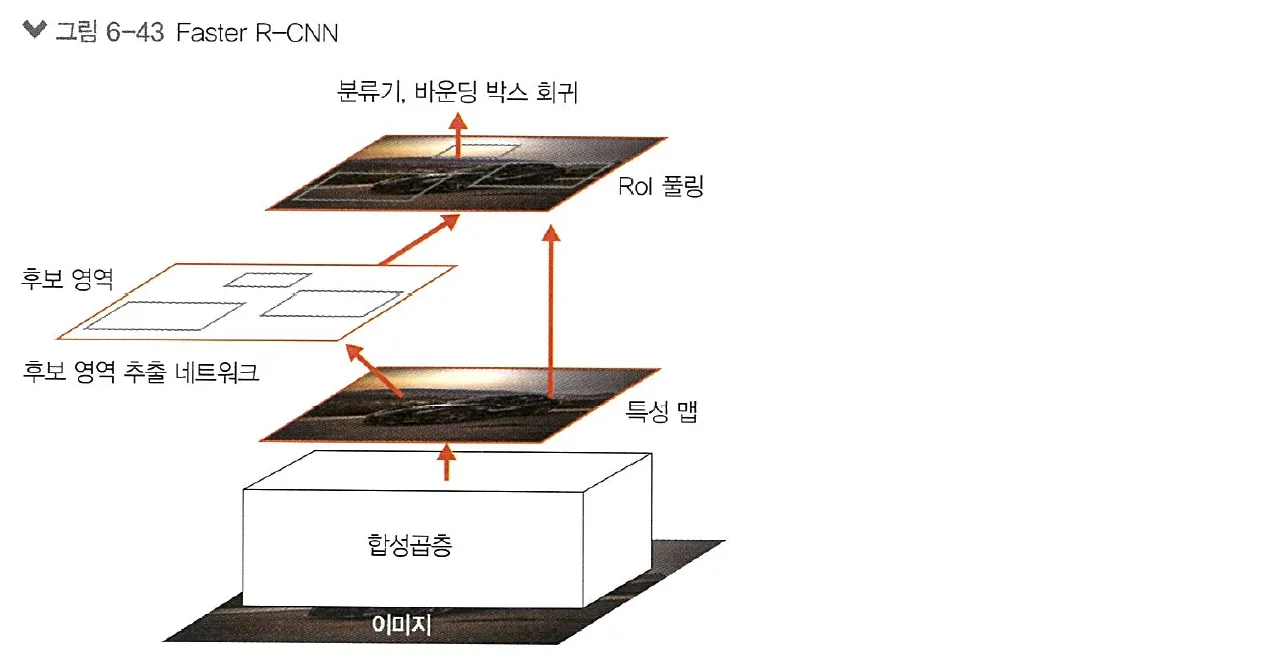
•
RPN은 그림처럼 마지막 합성곱층 다음에 위치하고, 그 뒤에 Fast R-CNN과 마찬가지로 RoI풀링과 분류기, 바운딩 박스 회귀가 위치함
◦
바운딩 박스 회귀: 바운딩 박스가 이미지의 객체를 정확히 포작하여 포함시킬 수 있도록 조정해 주는 역할을 함
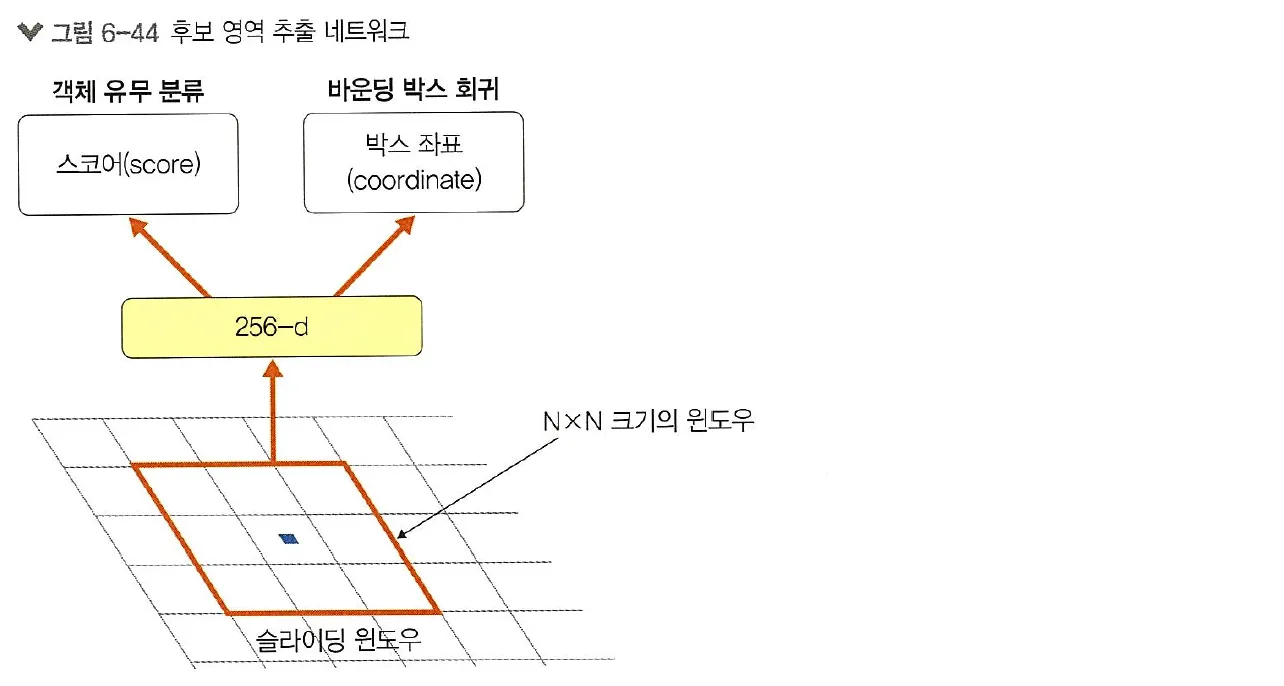
•
후보 영역 추출 네트워크는 특성 맵 N x N 크기의 작은 윈도우 영역을 입력으로 받고, 해당 영역에 객체의 존재 유무 판단을 위해 이진 분류를 수행하는 작은 네트워크를 생성함
•
R-CNN, Fast R-CNN에서 사용되었던 바운딩 박스 회귀 또한 위치 보정(좌표점 추론)을 위해 추가함
•
또한, 하나의 특성 맵에서 모든 영역에 대한 객체의 존재 유무를 확인하기 위해서는 슬라이딩 윈도우 방식으로 앞서 설계한 작은 윈도우 영역(N x N 크기)을 이용하여 객체를 탐색함
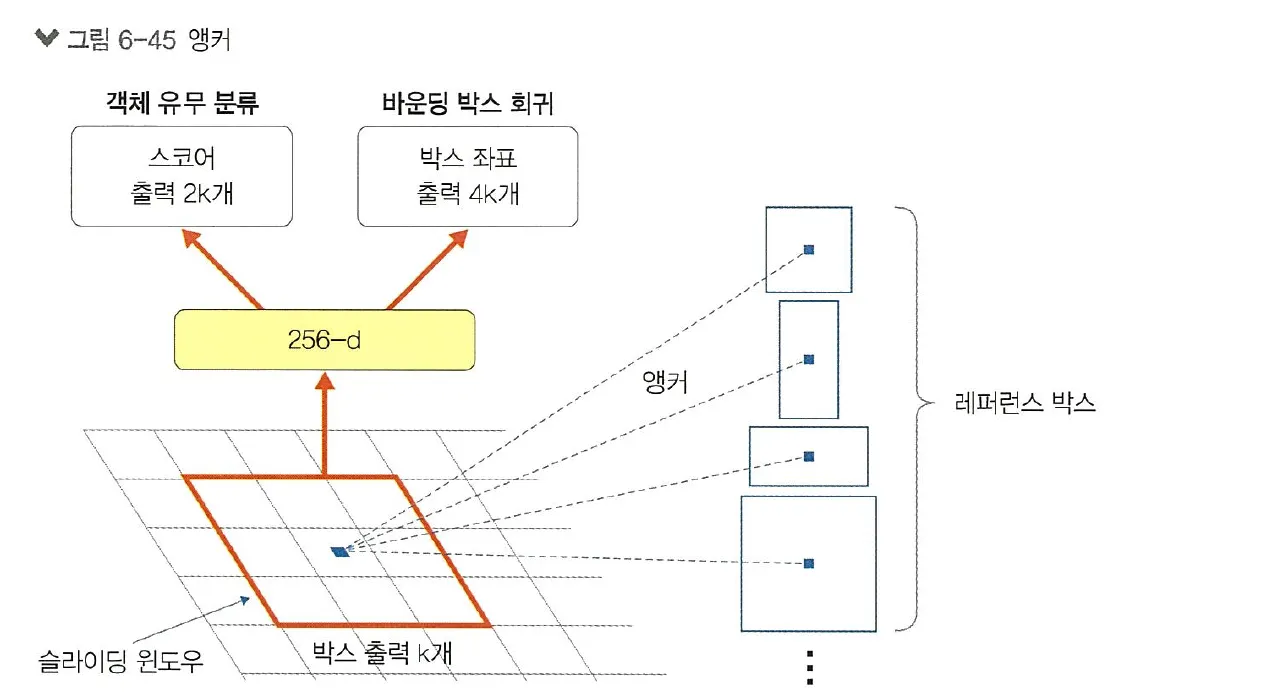
•
후보 영역 추출 네트워크는 이미지에 존재하는 객체들의 크기와 비율이 다양하기 때문에 고정된 N x N 크기의 입력만으로 다양한 크기와 비율의 이미지를 수용하기 어려운 단점이 있음
•
이러한 단점을 보완하기 위해 여러 크기와 비율의 레퍼런스 박스 k개를 미리 정의하고 각각의 슬라이딩 윈도우 위치마다 박스 k개를 출력하도록 설계하는데, 이 방식을 앵커(anchor)라고 함
•
즉, 후보 영역 추출 네트워크의 출력 값은 모든 앵커 위치에 대해 각각 객체와 배경을 판단하는 2k개의 분류에 대한 출력과 x, y, w, h 위치 보정 값을 위한 4k개의 회귀 출력을 갖음
•
예를 들어 특성 맵 크기가 w * h라면 하나의 특성 맵에 앵커가 총 w * h * k개 존재함