

본인이 공부했던 해당 주차 세션을 본인 나름대로 정리해주세요!
LEVEL.1 → 세션 내용과 PPT를 살펴보면서 정리해주세요! 마지막에는 본인이 진행했던 실습문제와 과제 풀이를 넣어주시면 됩니다.
LEVEL.2 → 세션 내용과 PPT, 그리고 교재의 내용을 토대로 정리해주세요! 마지막에는 실습문제 및 과제 Colab 노트 링크(누구나 볼 수 있게 권한 설정 꼭 해주세요)를 첨부해주세요
.png&blockId=6ecba8b1-9eb6-4dff-9f42-fe377ac90d39)
1주차 세션 정리
9장 데이터 분석 기초
파일에서 데이터 읽어 들이기
csv 파일 읽어 들이기
csv 파일을 컴퓨터에 저장한 후, 코랩에 코드를 실행한다.
from google.colab import files
uploaded = files.upload()
Python
복사
코드를 실행하면 파일을 업로드 할 수 있는 [파일 선택] 버튼이 나온다. 해당 버튼 누른 후 저장해둔 파일 업로드 하면 된다.
import csv
f= open('card.csv', encoding='utf8') # open() : csv 파일을 열어주는 함수
data = csv.reader(f) # .reader() : csv를 읽어주는 함수
next(data)
data = list(data)
print(data)
Python
복사
그리고 import csv로 라이브러리를 추가한 후, open() 명령어로 csv 파일을 열어준다. 그리고 .reader() 명령어로 csv를 읽어와서 data에 저장한다. print() 명령어로 저장된 데이터 확인 가능.
이 때 card.csv로 예시 들어서 사용
이 때, next() 명령어를 사용하는 이유는 헤더를 건너뛰고 불러들이기 위해서임
원하는 데이터 추출
불러온 데이터의 첫 행을 출력하려면 인덱스를 사용해야 함
print(data[0])
Python
복사
실행하면 data가 현재 리스트 타입이기 때문에 첫 행이 출력이 됨
여러 행 한꺼번에 출력
마찬가지로 인덱스를 활용해서 출력하면 된다.
print(data[:3])
Python
복사
: 앞에 숫자가 없기 때문에 인덱스 0부터 2까지 출력이 된다. 여러 행을 한 번에 출력하면 결과가 이차원 리스트로 출력이 됨
특정 값 골라서 출력
특정 하나만 출력하는 것도 이차원 리스트와 같게 하면 됨.
print(data[0][6])
Python
복사
data[0] 행의 인덱스 6이 출력이 된다.
이 때, 여러 행을 한 번에 보여주려면 연달아 작성해 주면 된다.
반복문으로 데이터 추출하기
for문을 사용해서 데이터를 추출할 수 있다.
for row in data:
print(row)
Python
복사
기존에 그냥 print(data)와는 다르게 row라는 변수 안에 저장된 데이터가 한 줄이 출력 되면 다시 처음으로 돌아가서 리스트가 끝날 때까지 출력이 된다.
이 때 열 인덱스를 넣어주면 해당 인덱스에 있는 요소들만 출력이 된다.
for row in data:
print(row[6])
Python
복사
위의 코드는 열 인덱스 6, 즉 7번째 요소를 출력한다. 한줄씩 7번째 요소가 쭉쭉 출력이 된다.
마찬가지로 print() 명령어 안에 여러 인덱스를 넣으면 해당 요소만 골라서 출력이 된다.
for row in data:
print(row[0], row[5], row[6])
Python
복사
열 인덱스 0, 5, 6 즉 첫 번째, 여섯 번째, 일곱 번째 요소가 출력이 된다.
그냥 데이터만 출력하는 것이 아닌, 데이터 타입 출력도 가능하다.
for row in data:
payment = int(row[6])
print(payment, type(payment))
Python
복사
payment라는 변수에 row[6]을 넣고 출력하고, type(payment)로 payment 변수의 타입도 출력된다.
마찬가지로 변수에 데이터를 넣은 것을 활용해서 문장을 완성할 수도 있다.
for row in data:
payment = int(row[6])
store = row[5]
print(store, '에서', payment, '원 결제')
Python
복사
반복문이 끝날 때까지 한 줄마다 인덱스 6과 5가 변수에 들어가 출력되며, 사이에 문자열도 출력이 된다.
또, 해당 데이터는 카드 사용 내역이 출력이 되는데 그 중 이용일시가 있다. 년도, 월, 일, 그리고 시간까지 있는데 이것이 하나의 요소 안에 들어가 있기에 시간을 제외하고 출력하고 싶다면 split() 명령어를 사용해야 한다.
for row in data:
date = row[0].split()[0]
payment = int(row[-3])
store = row[-4]
print(date, store, '에서', payment, '원 결제')
Python
복사
마찬가지로 변수를 활용하여 출력하는데, date라는 변수에 split() 명령어로 공백을 기준으로 값을 나눈다. row[0]을 나누는 것이기 때문에 '년도-월-일 시간' 을 ['년도-월-일', '시간']으로 나뉘게 된다. 이 때 시간을 제외하고 출력하기 위해 첫 번째, 즉 인덱스 0을 넣어준다. 그리고 그 값이 저장된 date라는 변수를 출력하면 이용일시 중 날짜만 나오게 출력할 수 있다.
반복문과 조건문으로 데이터 추출
for row in data:
if row[-1] == '전표매입':
print('구매확정!')
else:
print('취소!')
Python
복사
해당 데이터를 예시로, for문 안에 if문을 넣어 data의 -1 인덱스, 즉 뒤에서 첫 번째 요소에 '전표매입'이 있을 경우 '구매확정!'을, 그 외에는 모두 '취소!'를 출력하게 하는 코드이다.
데이터 분석
총 지출액 구하기
가지고 있는 카드 이용 내역 데이터로 총 지출액을 구하는 코드이다.
spend = 0 #1
for row in data: #2
if row[-1] == '전표매입' : #3
payment = int(row[-3]) #4
spend += payment #5
print(spend) #6
Python
복사
#1. spend라는 빈 변수를 만든다.
#2. for문으로 row에 저장된 데이터를 처음부터 끝까지 반복한다.
#3. 데이터의 맨 뒤에서 첫 번째 요소가 '전표매입일 경우',
#4. payment라는 변수에 데이터의 뒤에서 3번째 요소를 저장한다.
#5. spend 변수에 payment값을 더한다.
#6. spend 변수를 출력한다.
전체적으로 봤을 때, 전표매입이 있을 경우에 payment 변수를 spend 변수에 계속해서 더하는 코드이다. 결과적으로 총 지출액을 뽑을 수 있다. 이 때 print(spend) 앞에 들여쓰기를 넣어서 반복문 내부에 넣을 경우 반복할 때마다 실행이 되어 더해지는 과정을 볼 수 있다.
월별 지출액 그래프 그리기
s_mon = [0,0,0] #1
for row in data : #2
if row[-1] == '전표매입': #3
mon, payment = int(row[0].split('-')[1]), int(row[-3]) #4
idx = mon - 10 #5
s_mon[idx] += payment #6
print(s_mon) #7
Python
복사
#1. s_mon이라는 리스트를 생성한다.
#2. for문으로 row에 저장된 데이터를 처음부터 끝까지 반복한다.
#3. 데이터의 맨 뒤에서 첫 번째 요소가 '전표매입일 경우',
#4. mon이라는 변수에 split() 명령어로 '-'을 기준으로 나누고, 인덱스 1로 두 번째 요소를 뽑는다. payment 변수에는 데이터의 뒤에서 3번째 요소를 넣는다.
#5. idx라는 변수에 mon에서 1을 뺀 0, 1, 2를 넣는다. (10월, 11월, 12월밖에 없는 데이터라서)
#6. s_mon 데이터에서 idx 변수를 인덱스로 넣어 0, 1, 2로 활용해 idx가 0일 때의 payment는 s_mon[0]에 계속 더해주고, 1, 2 역시 s_mon[1], s_mon[2]에 넣는다.
#7. print(s_mon)을 출력해서 월별 지출액을 출력한다.
마찬가지로 계속 값이 더해져서 나오며, 인덱스를 사용해 월별로 지출액이 나온다. 아래는 같은 값이 출력되는 코드이다.
s_mon = [0,0,0]
for row in data :
if row[-1] == '전표매입':
s_mon[int(row[0].split('-')[1])-10] += int(row[-3])
print(s_mon)
Python
복사
같은 결과가 출력이 된다. s_mon에 바로 대괄호를 활용해 인덱스로 사용을 했다. -10을 해주어 0, 1, 2을 만들었다.
해당 값으로 그래프를 출력한다면
!sudo apt-get install -y fonts-nanum
!sudo fc-cache -fv
!rm ~/.cache/matplotlib -rf
Python
복사
import matplotlib.pyplot as plt
s_mon = [0, 0, 0]
for row in data :
if row[-1] == '전표매입':
mon, payment = int(row[0].split('-')[1]), int(row[-3])
idx = mon - 10 # 월이 10, 11, 12 월이라 값을 간단하게 하려고
s_mon[idx] += payment
plt.rc('font', family = 'NanumBarunGothic')
plt.title('10~12월 지출현황')
plt.bar(['10월', '11월', '12월'], s_mon, color='royalblue')
# plt.ticklabel_format(axis='y', style= 'plain') y축 지수 없애는 코드
plt.show()
Python
복사
한글 타이틀을 넣기 위해 먼저 코드를 실행하고, 라이브러리에서 matplotlib를 사용한다. 만약 런타임 다시 실행을 한다면 import csv도 다시 실행한다. 그리고 월별 매출액이 출력 된 값으로 막대그래프를 그려준다. 다만 그래프 맨 위에 단위인 1e6이 들어가고 y축이 1.0~4.0으로 출력이 되는데 지수를 없애주려면 주석 처리 돼있는 코드를 실행하면 됨
지출액 비교 그래프 그리기
taxi = [0, 0, 0]
for row in data:
if row[-1] == '전표매입' and '택시' in row[5]:
mon, payment = int(row[0].split('-')[1]), int(row[-3])
idx = mon-10
taxi[idx] += payment
print(taxi)
Python
복사
카드 이용값 중 택시를 이용한 값을 출력한다. 코드 작성 방식은 위와 같고, 그 중 and 명령어를 사용해서 데이터의 뒤에서 첫 번째 요소에 '전표매입'이 있고 앞에서 6번째 요소에 '택시'가 있는 것만 출력한다. 월별로 출력이 된다.
plt.rc('font', family = 'NanumBarunGothic')
plt.title('10~12월 지출현황')
plt.plot(['10월', '11월', '12월'], taxi, color='crimson', label='택시비 지출액')
plt.legend()
plt.show()
Python
복사
plot 명령어로 꺾은 선 그래프를 그려준다. 11월이 가장 높은 값이 나온다.
월별 배달음식비 지출액 그래프 그리기
deli = [0, 0, 0]
for row in data:
if row[-1] == '전표매입' and row[5] == '(주)우아한형제들':
mon, payment = int(row[0].split('-')[1]), int(row[-3])
idx = mon-10
deli[idx] += payment
plt.rc('font', family = 'NanumBarunGothic')
plt.title('10~12월 배달음식비 지출현황')
plt.plot(['10월', '11월', '12월'], deli, color='indigo', label='배달음식비 지출액')
plt.legend()
plt.show()
Python
복사
앞선 코드와 마찬가지로 월별 지출액을 뽑는데, 이번에는 택시가 아니라 '(주)우아한형제들'이 들어가는 것을 찾는다. 그리고 마찬가지로 plot 명령어로 이용해 꺾은선 그래프를 그려준다.
비교 그래프 그리기
plt.rc('font', family = 'NanumBarunGothic')
plt.title('10~12월 택시비/배달음식비 지출현황')
plt.plot(['10월', '11월', '12월'], taxi, color='crimson', label='택시비 지출액')
plt.plot(['10월', '11월', '12월'], deli, color='indigo', label='배달음식비 지출액')
plt.legend()
plt.show()
Python
복사
택시비와 배달음식비 지출을 비교하기 위한 그래프를 그린다. 꺾은선 그래프로 그려지며, 같이 작성하면 두 그래프가 동시에 그려진다.
지출액 상위 10개 항목 뽑기
가맴정별 지출액을 저장하는 딕셔너리 만들기
spending = {} #1
for row in data: #2
if row[-1] == '전표매입' : #3
store, payment = row[-4], int(row[-3]) #4
if store not in spending.keys() : #5
spending[store] = payment #6
else: #7
spending[store] += payment #8
print(spending) #9
Python
복사
#1. spending이라는 빈 딕셔너리를 만든다.
#2. for문으로 row에 저장된 데이터를 처음부터 끝까지 반복한다.
#3. 데이터의 맨 뒤에서 첫 번째 요소가 '전표매입일 경우',
#4. store라는 변수에 데이터의 뒤에서 4번째 요소를 넣고, payment라는 변수에 데이터의 뒤에서 3번째 요소를 넣으며 int 명령어로 정수형으로 만들어준다.
#5. store 변수가 spending 딕셔너리의 키값에 없을 경우,
#6. spending 딕셔너리에 store를 키로, payment를 값으로 하는 요소를 추가한다.
#7. 그 외에는,
#8. spending 딕셔너리에 store를 키로 하는 요소에 payment를 값으로 더해준다.
#9. print(spending)으로 출력한다.
가맴정명이 있을 경우에는 값을 계속해서 더해주고, 없을 경우에는 새로운 딕셔너리로 만들어서 넣는다.
지출액 상위 10개 가맹점 골라 그래프 그리기
import operator
import matplotlib.pyplot as plt
spending = {}
for row in data:
if row[-1] == '전표매입' :
store, payment = row[-4], int(row[-3])
if store not in spending.keys() :
spending[store] = payment
else:
spending[store] += payment
top10 = sorted(spending.items(), key = operator.itemgetter(1), reverse=True)[:10]
top10_store=[]
top10_amount = []
for t in top10:
top10_store.append(t[0])
top10_amount.append(t[1])
plt.rc('font', family = 'NanumBarunGothic')
plt.title('10~12월 지출 TOP 10')
plt.barh(top10_store, top10_amount, color = 'b')
plt.show()
Python
복사
top10이라는 변수에 payment(값)을 기준으로 딕셔너리를 내림차순 정렬한 다음, 앞에서 10개 요소를 뽑아 저장한다. 그리고 top10_store와 top10_amount라는 빈 리스트를 만들고 for 문에서 append() 명령어를 이용해 각자 상위 10개의 가맹점명과 지출액을 각각 리스트에 저장한다. 그리고 두 리스트를 사용해서 막대그래프를 그림
.png&blockId=76e47f5d-9747-44af-8a58-8590a253a958)
실습문제 정리
1번
다음 그래프를 그려 보세요.
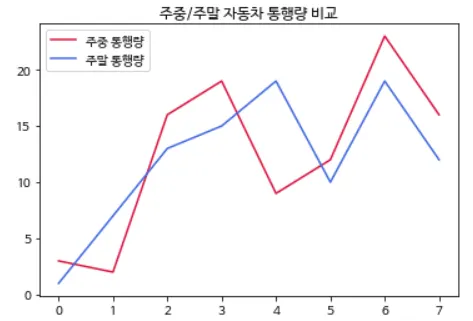
[조건]
•
x축 눈금은 편의상 숫자 0부터 7까지로 한다.
•
주중 통행량 그래프 색상은 crimson, 주말 통행량 그래프 색상은 royalblue이다.
[정답]
!sudo apt-get install -y fonts-nanum
!sudo fc-cache -fv
!rm ~/.cache/matplotlib -rf
Python
복사
import matplotlib.pyplot as plt
weekday = [3, 2, 16, 19, 9, 12, 23, 16] # 주중 자동차 통행량
weekend = [1, 7, 13, 15, 19, 10, 19, 12] # 주말 자동차 통행량
plt.rc('font', family='NanumBarunGothic')
plt.title('주중/주말 자동차 통행량 비교')
plt.plot(range(8), weekday, label='주중 통행량', color='crimson')
plt.plot(range(8), weekend, label='주말 통행량', color='royalblue')
plt.legend()
plt.show()
Python
복사
정답을 설명해주세요.
plt.title() 명령어를 통해 '주중/주말 자동차 통행량 비교' 를 제목으로 넣는다. 이 때 한국어로 제목을 넣기 때문에 plt.rc('font', family='NanumBarunGothic') 을 통해 한글 글꼴을 지정한다. 그러나 그냥 이 코드만 실행하면 되지 않으므로, 첫 번째에 있는 코드를 먼저 실행한 후 해준다. 다음으로 plt.plot() 으로 꺾은선 그래프를 그려주는데, 조건 중 0부터 7까지로 하기 때문에 range(8)로 x축을 지정해준다. 그리고 주중 자동차 통행량의 데이터인 weekday를 먼저 그려주는데, color 명령어로 색깔을 지정하고, label로 범례를 넣는다. 그림과 같이 넣어주고, 그래프를 겹쳐 그려야 하므로 같은 함수를 작성한다. x축이 같아야 하니 똑같이 range(8)을 작성해주고, label과 color도 넣어준다. 범례를 넣으면 plt.legend()도 필수이니 써주고, 마지막으로 plt.show() 명령어를 넣어준다.다음 그래프를 그려보세요.
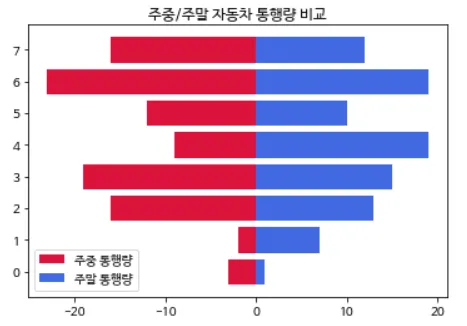
[조건]
•
x축 눈금은 편의상 숫자 0부터 7까지로 한다.
•
주중 통행량 그래프 색상은 crimson, 주말 통행량 그래프 색상은 royalblue이다.
2번
[정답]
import matplotlib.pyplot as plt
weekday = [3, 2, 16, 19, 9, 12, 23, 16]
weekend = [1, 7, 13, 15, 19, 10, 19, 12]
for i in range(len(weekday)):
weekday[i] = -weekday[i]
plt.rcParams['axes.unicode_minus'] = False
plt.rc('font', family='NanumBarunGothic')
plt.title('주중/주말 자동차 통행량 비교')
plt.barh(range(8), weekday, label='주중 통행량', color='crimson')
plt.barh(range(8), weekend, label='주말 통행량', color='royalblue')
plt.legend()
plt.show()
Python
복사
정답을 설명해주세요.
가로형 막대그래프를 겹쳐 그려주는 것으로, plt.barh()를 2개 써준다. for문으로 첫 번째 믹대그래프의 값을 음수로 만들어야 한다. 왼쪽 그래프는 주중 통행량이므로 week[i] = -week[i]를 써준다. 또 x축의 - 기호를 인식하도록 plt.rcParams['axes.unicode_minus'] = False를 추가한다. 그리고 plt.title()로 제목을 추가하고, 역시나 x축이 0부터 7이므로 range(8)을 넣고, label을 추가하며 색도 같이 넣어준다. 그리고 범례를 넣었으니 plt.legend()를 추가하고, 마지막으로 plt.show()를 넣는다.3번.
다음 그래프를 그려 보세요.
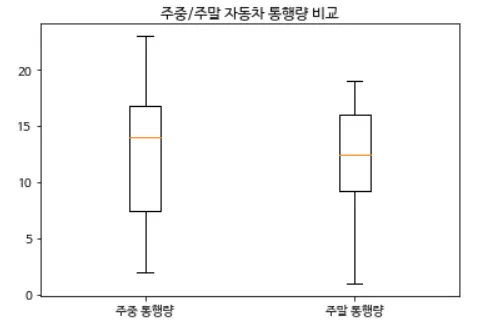
[정답]
weekday = [3, 2, 16, 19, 9, 12, 23, 16]
weekend = [1, 7, 13, 15, 19, 10, 19, 12]
plt.rc('font', family='NanumBarunGothic')
plt.title('주중/주말 자동차 통행량 비교')
plt.boxplot([weekday, weekend], labels=['주중 통행량', '주말 통행량'])
plt.show()
Python
복사
정답을 설명해주세요.
상자 수염 그래프를 겹쳐 그리려면 plt.boxplot() 에 이차원 리스트를 넣으면 된다.
plt.title()로 제목을 추가하고, 이차원 리스트를 넣고 라벨을 추가해주면 된다. 그리고 마지막에 plt.show()를 추가한다..png&blockId=fd31bd44-79b7-4363-9ef3-c58288ca09a6)
과제 제출
1번
card.csv 파일은 10월부터 12월까지 3개월간의 카드 이용내역을 담은 파일입니다. 카드 이용내역에는 승인거래와 취소거래가 섞여 있습니다. 카드 이용내역 중 취소거래의 총액을 구하는 코드를 작성하세요.
[힌트]
1. 매입상태가 전표매입이 아닌 건은 모두 취소거래입니다.
2. 취소거래의 총액을 저장하는 변수가 있어야 합니다.
[정답]
from google.colab import files
uploaded = files.upload()
Python
복사
import csv
f= open('card.csv', encoding='utf8') # open() : csv 파일을 열어주는 함수
data = csv.reader(f) # .reader() : csv를 읽어주는 함수
next(data)
data = list(data)
print(data)
Python
복사
cancle = 0
for row in data:
if row[-1] != '전표매입' :
payment = int(row[-3])
cancle += payment
print(cancle)
Python
복사
[실행 결과]
3245797
Python
복사
정답을 설명해주세요.
코랩에서 코드를 사용하기 위해 첫 번째 코드를 실행한 후 csv 파일을 불러온다. 그리고 import 명령어로 csv 라이브러리를 불러오고, csv 파일을 불러온다. 세 번째 코드에서 cancle이라는 변수를 만들어주고 초기값을 0으로 지정해준다. 그리고 for문으로 데이터를 처음부터 끝까지 실행하게 만들어주고, row[-1]로 데이터의 뒤에서 첫 번째 요소에 '전표매입'이 없을 경우 payment 변수에 row[-3], 즉 데이터의 뒤에서 세 번째 요소를 저장한다. 이때 정수값으로 저장하도록 int 명령어를 사용해준다. 그리고 같은 조건으로 cancle 변수에 payment를 계속 더해주도록 한다. 마지막으로 print() 명령어로 결과를 출력한다.2번
card.csv 파일의 카드 이용내역에서 월별로 백화점에서 사용한 금액을 꺾은선 그래프로 그리세요. 그래프 이름은 '10~12월 백화점 지출액'으로 합니다.
[힌트]
1. 그래프를 그리려면 10~12월 백화점 지출액을 하나의 리스트로 저장해야 합니다.
2. 백화점 지출액은 가맹점명에 '백화점' 키워드가 들어 있습니다.
[정답]
!sudo apt-get install -y fonts-nanum
!sudo fc-cache -fv
!rm ~/.cache/matplotlib -rf
Python
복사
import matplotlib.pyplot as plt
department = [0, 0, 0]
for row in data:
if row[-1] == '전표매입' and '백화점' in row[5]:
mon, payment = int(row[0].split('-')[1]), int(row[-3])
idx = mon-10
department[idx] += payment
plt.rc('font', family = 'NanumBarunGothic')
plt.title('10~12월 백화점 지출액')
plt.plot(['10월', '11월', '12월'], department, color='violet')
plt.show()
Python
복사
[실행 결과]
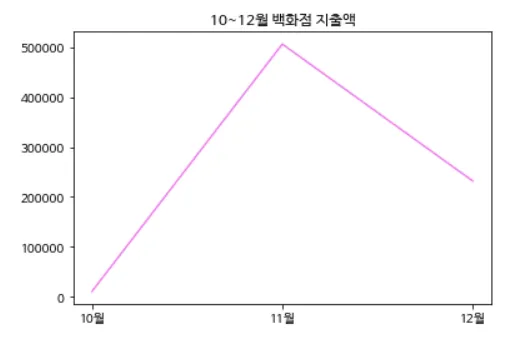 정답을 설명해주세요.
정답을 설명해주세요.그래프를 그리기 위해 import matplotlib.pyplot as plt를 실행하고, department라는 빈 리스트를 만든다. 그리고 데이터의 뒤에서 첫 번째 요소가 '전표매입'이고, 6번째 요소에 '백화점'이 들어있을 때, mon이라는 변수에 row[0]의 요소를 split() 명령어를 사용해 '-'를 기준으로 나눴을 때 두 번째 요소를 저장하고, payment 변수에 뒤에서 3번째 요소를 저장한다. 그리고 idx 변수에 mon 변수에서 10을 뺀 수를 저장하는데, 10, 11, 12월 밖에 없으니 0, 1, 2가 저장된다. department에 인덱스를 idx를 넣고, 인덱스가 0일 때, 즉 10월일 때 그에 대응하는 payment를 저장하고, 1일 때는 11월의 payment, 2일 때는 12월의 payment를 저장한다. 그리고 plot 명령어로 꺾은선 그래프를 그려준다.
11장 프로젝트로 파이썬 완성하기 : 핫플레이스 인구 분석
11.1 프로젝트 목표 수립하기
11.1.1 데이터 선정하기
데이터를 선정하기 위해 구글에서 데이터를 찾는다. 서울의 시간대별 인구를 찾기 위해 서울열린데이터광장을 들어가준다. 그리고 데이터를 내려받는데 한 달을 기준으로 데이터가 올라와 있다. 2020년 1월부터 코로나 때문에 인구 이동이 감소됐으니 2019년 12월 데이터로 내려받는다. 파일을 받고 압축을 해제하면 csv 파일이 있다. 그 중 행정동코드가 있는데 이를 위해 자치구 단위의 행정구역 코드정보를 받는다. 그리고 csv 라이브러리를 사용할 수 있도록 xlsl 파일을 csv 파일로 저장한다.
11.1.2 목표 수립하기
프로젝트의 목표를 수립해야 하는데, 우리는 해당 데이터로 핫플레이스가 덜 붐비는 시간을 알고 싶기 때문에 프로젝트의 목표는 핫플레이스가 있는 핫플레이스가 있는 행정동에서 인구가 가장 적은 시간대 파악하기로 정한다. 이에 대한 하위 목표로 핫플레이스가 있는 행정동의 시간대별 평균인구 그래프를 그려 분석하기로 정한다.
그리고 두 번째 목표는 핫플레이스가 있는 행정동의 주중/주말 시간대별 평균인구 그래프를 그려 분석하기로 정한다.
그리고 세번째 목표는 핫플레이스가 있는 행정동의 남녀 시간대별 평균인구 그래프를 그려 분석하기로 한다. 이에 대한 하위 목표로 핫플레이스가 있는 행정동과 나에게 익숙한 행정동의 시간대별 평균인구 그래프를 그려 비교 분석하기로 정한다.
11.2 프로그램으로 구현하기
11.2.1 데이터 파일 읽고 행정동명과 행정동 코드 연결하기
파일을 읽어 들이는 코드를 작성한다.
from google.colab import drive
drive.mount('/content/gdrive')
Python
복사
import csv
f= open('/content/gdrimport csv
f= open('/content/gdrive/MyDrive/code_1202/LOCAL_PEOPLE_DONG_201912.csv', encoding='utf8') # open() : csv 파일을 열어주는 함수
data = csv.reader(f) # .reader() : csv를 읽어주는 함수
next(data)
data = list(data)
print(len(data))ive/MyDrive/code_1202/LOCAL_PEOPLE_DONG_201912.csv', encoding='utf8') # open() : csv 파일을 열어주는 함수
data = csv.reader(f) # .reader() : csv를 읽어주는 함수
next(data)
data = list(data)
print(len(data))
Python
복사
f2 = open('/content/gdrive/MyDrive/code_1202/dong_code.csv', encoding='cp949')
code_data = csv.reader(f2)
next(code_data)
next(code_data)
code_data = list(code_data)
print(len(code_data))
Python
복사
두 개의 csv 파일을 각각 f, f2에 저장한다. 이 때 두 번째 코드에서 next(code_data)를 두 번 실행하는 이유는 한글 헤더와 영문 헤더를 모두 제거하기 위함이다. (원 데이터의 헤더가 한글, 영어 헤더 두 개임)
그리고 csv 파일을 불러오면 실제 데이터가 숫자라도 문자열로 저장이 되기 때문에 데이터 타입을 변환해준다.
for row in data:
for i in range(1, 32):
if i <= 2: # 인덱스가 2 이하인 경우 정수형으로 변환
row[i] = int(row[i])
else: # 인덱스가 2 초과인 경우 실수형으로 변환
row[i] = float(row[i])
print(data[0])
Python
복사
해당 코드 데이터를 처음부터 끝까지 반복하는데, 데이터의 인덱스는 31까지 있기 때문에 range(1, 32)를 사용해준다. 이 때 인덱스 0을 제외한 이유는 기준일ID이기 때문인데, 날짜는 나중에 슬라이싱 해서 사용하려면 문자열이어야 하므로 제외한다. 그리고 if 문을 사용해 인덱스가 2 이하인 경우 row[i]를 정수형으로 변환하고, 그 외, 즉 인덱스가 2를 초과할 경우 실수형으로 변환하도록 해준다. 즉 인덱스 1, 2는 정수형으로 바꿔주는데, 시간대 구분과 행정동코드는 정수형이어도 되지만 이를 제외한 4번째 열인 총생활 인구수부터 마지막 열까지는 모두 소수점이 있는 실수이기 때문에 float() 명령어를 이용해 실수형으로 변환한다.
그리고 행정동코드를 보면 역시 모두 문자열로 저장되어 있는데, 이 중 사용할 항목은 두 번째 열인 행자부 행정동코드와 마지막 열인 행정동명이다. 행정동명은 문자열 그대로 사용하므로 두고, 행자부 행정동코드만 숫자형으로 변환해준다.
for row in code_data:
row[1] = int(row[1])
print(code_data[0])
Python
복사
for문을 사용해서 code_data에 있는 값을 row[1], 즉 2번째 열을 int() 명령어로 정수형으로 바꿔주는 반복문이다.
다음으로 행정동명과 행정동코드를 연결한다. 분석할 핫플레이스가 위치한 행정동을 선택해야하는데, 사용자가 알고 싶은 행정동명을 직접 입력하게 만든다.
dong_name = input('핫플레이스가 위치한 행정동을 입력하세요. --> ')
for row in code_data:
if row[-1] == dong_name:
dong_code = row[1]
print(dong_name, '-', dong_code, '을(를) 분석합니다!')
Python
복사
dong_name 이라는 변수에 input() 명령어를 사용해 핫플레이스가 위치한 행정동을 입력 받도록 만든다. 그리고 code_data, 즉 행정동 코드 데이터의 맨 마지막 열(행정동명)이 input으로 입력 받은 값이랑 같다면, 해당하는 행정동코드를 변수 dong_code에 저장하는 코드이다. 마지막으로 print() 명령어를 이용해 입력한 행정동 이름과 행정동 코드를 출력하도록 한다.
앞 쪽에서 실행한 핫플레이스 인구 분석 프로젝트에서 실행해야 하는 기본 코드를 정리하면 다음과 같다.
import csv
f= open('/content/gdrive/MyDrive/code_1202/LOCAL_PEOPLE_DONG_201912.csv', encoding='utf8') # open() : csv 파일을 열어주는 함수
data = csv.reader(f) # .reader() : csv를 읽어주는 함수
next(data)
data = list(data)
print(len(data))
f2 = open('/content/gdrive/MyDrive/code_1202/dong_code.csv', encoding='cp949')
code_data = csv.reader(f2)
next(code_data)
next(code_data)
code_data = list(code_data)
print(len(code_data))
for row in data:
for i in range(1, 32):
if i <= 2: # 인덱스가 2 이하인 경우 정수형으로 변환
row[i] = int(row[i])
else: # 인덱스가 2 초과인 경우 실수형으로 변환
row[i] = float(row[i])
print(data[0])
for row in code_data:
row[1] = int(row[1])
print(code_data[0])
dong_name = input('핫플레이스가 위치한 행정동을 입력하세요. --> ')
for row in code_data:
if row[-1] == dong_name:
dong_code = row[1]
print(dong_name, '-', dong_code, '을(를) 분석합니다!')
Python
복사
하위 목표 1 - 시간대별 인구 분석하기
하위 목표 1 : 핫플레이스가 있는 행정동의 시간대별 평균인구 그래프를 그려 분석하기
먼저, 시간대별 평균인구를 저장할 리스트를 길이 24로 만들고 초기값 0을 저장한다. (시간은 0시부터 23시까지 있기 때문) x축으로 사용.
y축은 행정동의 시간대별 평균인구로, population으로 한다.
population = []
for i in range(24):
population.append(0)
Python
복사
빈 리스트인 population 안에 0을 추가하는 작업을 24번 반복하는 코드이다. 이 때 이 세 줄의 코드를 줄이는 방법이 있다.
population = [0 for i in range(24)]
print(len(population), population)
Python
복사
반복문을 리스트 안에 넣어 리스트를 만드는 동시에 초기화하는 방법으로, 리스트를 선언하고 대괄호 안에 초기값과 반복문을 넣어준다. 초기값은 0이고 24번 반복하는 코드이다. 이렇게 되면 .append() 함수가 빠지게 된다. 이를 리스트 내포라고 한다.
이것을 조금 변형하면 0부터 23까지 숫자를 차례대로 넣을 수 있다.
population = [i for i in range(24)]
print(len(population), population)
Python
복사
형식은 위의 코드와 똑같지만 초기값을 0 대신 i를 넣어 실행하면 숫자가 차례대로 저장된다.
위의 코드를 활용하여 그래프를 그리면 된다.
population = [0 for i in range(24)]
for row in data:
if row[2] == dong_code:
time, p = row[1], row[3]
population[time] += p
print(population)
Python
복사
우선 그래프를 그리기 전 코드를 보면 population이라는 빈 리스트에 0이 24번 반복되게 넣은 다음, 데이터의 3번째 열이 dong_code, 즉 행정동 코드와 같으면, 데이터의 두 번째 열인 시간대를 저장한 time과 데이터의 네 번째 열인 총생활인구수를 저장한 변수 p를 활용해 time이 population의 인덱스이므로 population[time]에 총생활인구수(p)를 계속 더하는 조건문이다. 따라서 시간대별로 총생활인구수가 계속 더해져 결과가 나온다.
앞의 코드를 줄이고 싶으면
for row in data:
if row[2] == dong_code:
population[row[1]] += row[3]
Python
복사
time과 p 변수를 쓰지 않아도 된다.
다음으로 리스트 내포를 활용해 population 리스트를 31로 나누어 시간대별 평균인구를 구한다. 이 때 값을 나누는 이유는 리스트에는 총 31일 간의 시간대별 인구 데이터가 들어있기 때문에 나누는 것이다.
population = [p/31 for p in population]
print(population)
Python
복사
population의 모든 요소가 31로 나뉘게 된다.
이제 그래프를 그릴 수 있는데, 꺾은 선 그래프로 그린다.
import matplotlib.pyplot as plt
population = [0 for i in range(24)]
for row in data:
if row[2] == dong_code:
time, p = row[1], row[3]
population[time] += p
population = [p/31 for p in population]
plt.rc('font', family='NanumBarunGothic')
plt.title(dong_name + ' 시간대별 평균인구')
plt.plot(range(24), population, color='indigo')
plt.xticks(range(24), range(24))
plt.xlabel('시간대')
plt.ylabel('평균인구수')
plt.show()
Python
복사
→ 실행결과
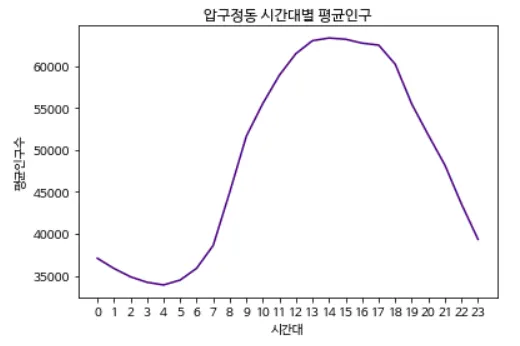
title을 dong_name 변수를 활용하여 작성하는데, 앞 쪽에 input으로 값을 입력할 때 압구정동을 넣었기 때문에 결과 역시 압구정동으로 출력이 된다. 그리고 plot() 명령어를 통해 그래프를 그리는데, range(24)로 x값을 0부터 23까지 넣는다. 그리고 xticks는 x축의 눈금을 나타내는 것으로 x축을 1시간 단위로 표기했다. (넣지 않으면 눈금이 5시간 단위로 표시됨)
11.2.3 하위 목표 2 - 주중/주말 시간대별 인구 분석하기
두 번째 하위 목표 : 핫플레이스가 있는 행정동의 주중/주말 시간대별 평균인구 그래프를 그려 분석하기
일단 주중과 주말을 구분하기 위해 datetime 라이브러리를 활용한다. date() 안에 연도, 월, 일을 순서대로 넣은 후 weekday()를 붙이면 월화수목금토일을 각각 숫자 0부터 6까지 나타낸다. 따라서 실행했을 때 0부터 4까지 숫자가 나오면 주중이고 5나 6이 나오면 주말이다.
아래는 2019년 12월 15일의 요일을 확인하는 코드이다.
import datetime
datetime.date(2019, 12, 15).weekday()
Python
복사
해당 코드를 실행할 시 6이 나온다. 즉, 일요일이다.
이를 활용해서 코드를 작성한다.
import datetime
weekday = [0 for i in range(24)]
weekend = [0 for i in range(24)]
for row in data:
if row[2] == dong_code:
time, p = row[1], row[3]
year, mon, day = int(row[0][:4]), int(row[0][4:6]), int(row[0][6:])
num = datetime.date(year, mon, day).weekday()
if num < 5:
weekday[time] += p
else:
weekend[time] += p
weekday_cnt, weekend_cnt = 0, 0
for i in range(1, 32):
if datetime.date(2019, 12, i).weekday() < 5:
weekday_cnt += 1
else:
weekend_cnt += 1
print('2019년 12월의 주중 일수 =', weekday_cnt, '주말 일수 =', weekend_cnt)
weekday = [w/weekday_cnt for w in weekday]
weekend = [w/weekend_cnt for w in weekend]
print('주중 인구:', weekday)
print('주말 인구:', weekend)
Python
복사
핫플레이스가 있는 행정동의 주중/주말 시간대별 평균인구 그래프를 그리는 코드이다. 주중 시간대별 생활인구를 저장할 리스트(weekday)와 주말 시간대별 생활인구를 저장할 리스트(weekend)를 길이 24로 만들고 초기값을 0으로 저장한다.
그리고 데이터의 3번째 열, 즉 인구 데이터의 행정동코드가 dong_code와 같을 시, 의 조건문을 생성한다. 해당 행의 시간대와 총생활인구수가 저장된 time과 p 변수, 그리고 기준일ID의 연도, 월, 일을 각각 변수에 저장한다. 그리고 그 년월일을 date(), weekday() 안에 넣어 주중과 주말을 구분하는 코드를 작성한다. 후에 조건문에서 num이 5보다 작을 시, 주중이 되니 weekday[time]에 p 값을 계속 더하고, 그 외 즉 주말은 weekend[time]에 p값을 계속 더하는 조건문을 추가한다.
반복이 끝나면 2019년 12월의 주중 일수와 주말 일수를 저장할 변수 두 개를 만들고 초기값 0을 저장한다. 그리고 반복문으로 12월의 일수만큼 반복한다. range(1, 32)를 쓰면 1부터 31까지 반복이다. 그리고 요일을 출력했을 때 5보다 작으면, 즉 주중이면 weekday_cnt에 1을 더하고, 그 외 즉 주말에는 weekend_cnt에 1을 더한다.
그리고 그 두 변수로 2019년 12월의 총 주중 일수와 주말 일수를 출력할 수 있다.
이제 앞에서 만들었던 주중 리스트 weekday를 weekday_cnt로, 주말 리스트 weekend를 주말 일수 weekend_cnt로 나누어 주중과 주말 평균인수를 구한다.
그리고 weekday와 weekend를 출력하면 시간대별로 주중과 주말 인구가 출력된다.
import matplotlib.pyplot as plt
plt.rc('font', family='NanumBarunGothic')
plt.title(dong_name + ' 주중/주말 시간대별 평균인구')
plt.plot(weekday, color='indigo', label='주중')
plt.plot(weekend, color='orangered', label='주중')
plt.legend()
plt.xlabel('시간대')
plt.ylabel('평균인구수')
plt.xticks(range(24), range(24))
plt.show()
Python
복사
→ [실행 결과]
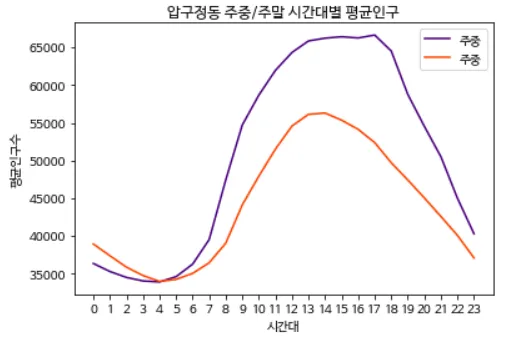
그래프 결과이다.
plt.figure(figsize=(20, 10))
plt.rc('font', family='NanumBarunGothic')
plt.title(dong_name + ' 주중/주말 시간대별 평균인구')
plt.bar(range(0, 72, 3), weekday, color='indigo', label='주중')
plt.bar(range(1, 72, 3), weekend, color='orangered', label='주말')
plt.legend()
plt.xlabel('시간대')
plt.ylabel('평균인구수')
plt.xticks(range(0, 72, 3), range(24))
plt.show()
Python
복사
→ [실행 결과]
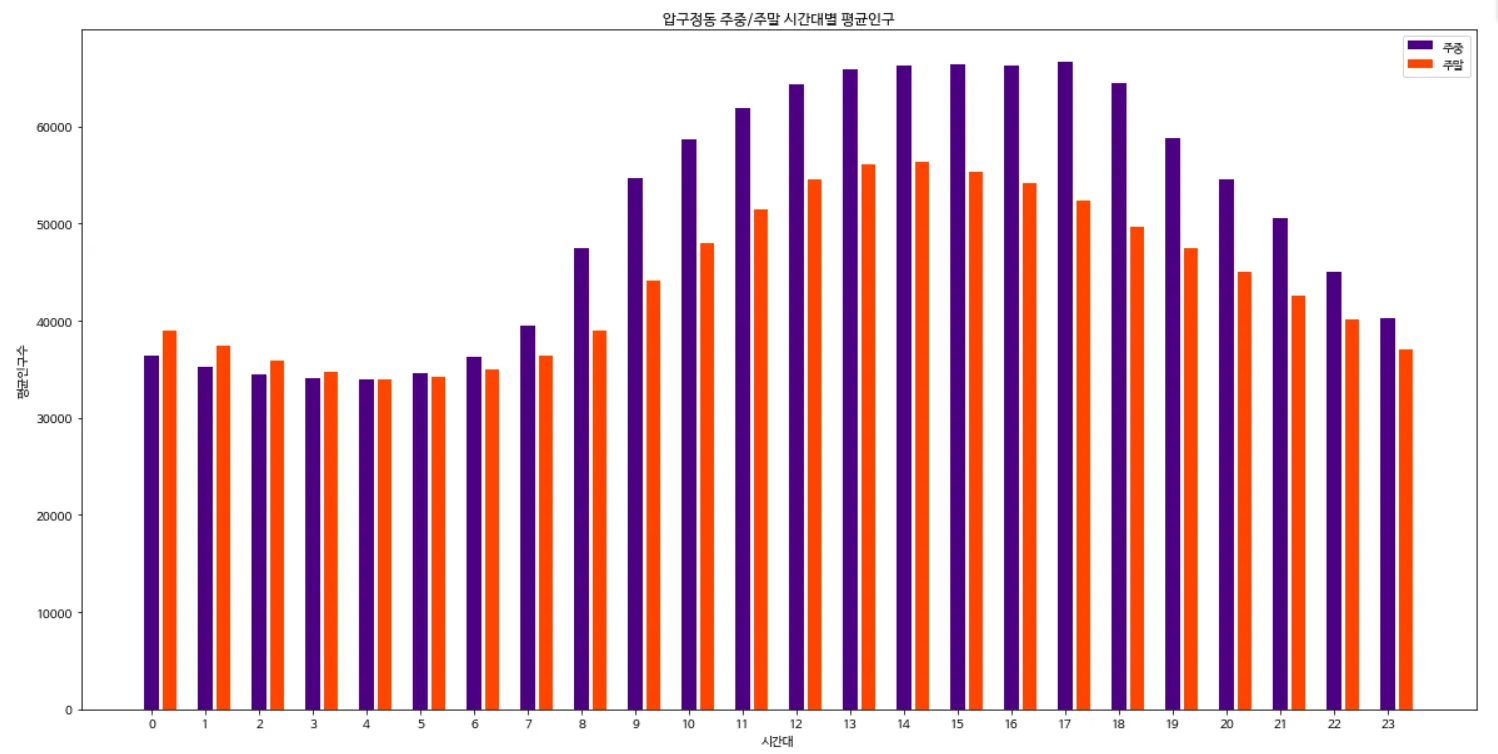
11.2.4 하위 목표 3 - 남녀 시간대별 평균인구 분석하기
세 번째 하위 목표 : 핫플레이스가 있는 행정동의 남녀 시간대별 평균인구 그래프를 그려 분석하기
male = [0 for i in range(24)]
female = [0 for i in range(24)]
for row in data:
if row[2] == dong_code:
time = row[1]
male[time] += sum(row[4:18])
female[time] += sum(row[18:32])
male = [m/31 for m in male]
female = [f/31 for f in female]
plt.rc('font', family='NanumBarunGothic')
plt.title(dong_name + ' 남녀 시간대별 평균인구')
plt.plot(male, color='b', label='남성')
plt.plot(female, color='r', label='여성')
plt.legend()
plt.xlabel('시간대')
plt.ylabel('평균인구수')
plt.xticks(range(24), range(24))
plt.show()
Python
복사
→ [실행 결과]
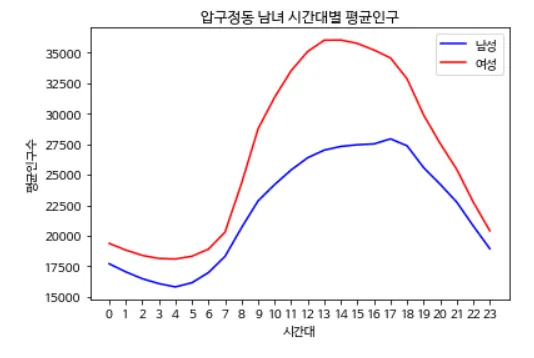
male과 female이라는 길이 24의 리스트를 만들고 초기값 0을 저장한다.
그리고 for 반복문으로 행정동 코드가 인구 데이터의 행정동 코드와 같을 시, 해당 시간대를 time 변수에 저장하고 male 리스트에 time 인덱스 값에 열 인덱스 4부터 17까지의 합을 더한다. 그리고 인덱스 18부터 32까지의 합은 female[time]에 저장한다. 그리고 반복이 끝나면 남성 생활인구 리스트 male과 여성 생활 인구 리스트 female을 각각 31로 나누어 시간대별 평균 인구를 구한다. 그리고 해당 데이터로 그린 그래프이다.
import matplotlib
male = [-m for m in male]
matplotlib.rcParams['axes.unicode_minus'] = False
plt.rc('font', family='NanumBarunGothic')
plt.title(dong_name + ' 남녀 시간대별 평균인구')
plt.barh(range(24), male, color='b', label='남성')
plt.barh(range(24), female, color='r', label='여성')
plt.legend()
plt.xlabel('시간대')
plt.ylabel('평균인구수')
plt.show()
Python
복사
→ [실행 결과]
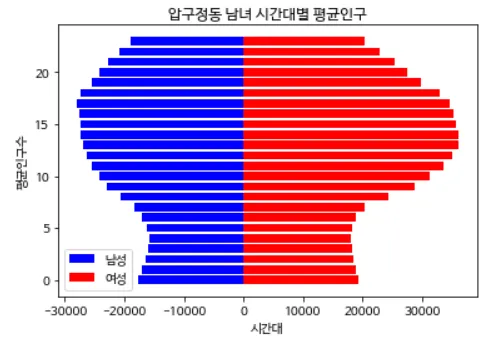
같은 데이터로 그린 다른 그래프이다. 남성 평균인구를 왼쪽에 여성 평균인구를 오른쪽에 두기 때문에 데이터를 음수 처리한다.
11.2.5 하위 목표 4 - 다른 지역과 인구 비교 분석하기
dong_name = input('핫플레이스가 위치한 행정동을 입력하세요. --> ')
for row in code_data:
if row[-1] == dong_name:
dong_code=row[1]
dong_name2 = input('비교할 행정동을 입력하세요. --> ')
for row in code_data:
if row[-1] == dong_name2:
dong_code2 = row[1]
Python
복사
import matplotlib.pyplot as plt
population = [0 for i in range(24)]
population2 = [0 for i in range(24)]
for row in data:
if row[2] == dong_code:
time, p = row[1], row[3]
population[time] += p
elif row[2] == dong_code2:
time, p = row[1], row[3]
population2[time] += p
population = [p/31 for p in population]
population2 = [p/31 for p in population2]
plt.rc('font', family='NanumBarunGothic')
plt.title(dong_name + '과 ' + dong_name2 + ' 남녀 시간대별 평균인구')
plt.plot(population, color='m', label=dong_name)
plt.plot(population2, color='orange', label=dong_name2)
plt.legend()
plt.xlabel('시간대')
plt.ylabel('평균인구수')
plt.xticks(range(24), range(24))
plt.show()
Python
복사
→ [실행 결과]
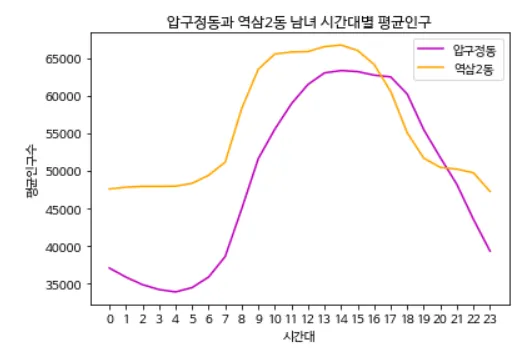
데이터의 인덱스 2가 dong_code와 같을 시, 해당 행의 시간대와 총생활인구수를 각각 time과 p 변수에 저장하고, 인덱스가 time인 population 리스트에 총생활인구수를 더한다. 그리고 인덱스 2가 dong_code2와 같을 시, 해당 행의 time과 p를 population2의 인덱스인 time에 총생활인구수를 더한다. 그리고 population과 population2를 31로 나눈 값을 다시 저장하고, 그 값으로 그래프를 그린다.