

이 줄 아래에 질문 작성해주시면 됩니다!
<형식>
작성자
질문할 내용이 있는 챕터 번호
질문할 내용
황현수
1.2 출력층
이진 분류에서는 출력층의 활성화 함수로 시그모이드 함수를 사용하기도 합니다.
이진 분류에서도 소프트맥스 함수가 시그모이드보다 모델 학습에 유리한지 궁금합니다.
소프트맥스 활성화 함수는 0~1까지 입력받은 값을 출력으로 0~1사이의 값으로 모두 정규화하며 출력 값들의 총합은 항상 1이 되는 특성을 가진 함수입니다. 즉, 다중 분류에서 활용할 경우 효율적이라는 뜻입니다. 합성곱 신경망은 주로 이미지처리에 쓰입니다. 예측 확률도 산출할 수 있습니다. 이미지는 단순히 이진분류로 처리할 수 없기 때문에 소프트맥스를 사용하는 것입니다.
소프트맥스 함수는 input이 여러개일때도 시그모이드를 사용 가능하게 일반화한 것입니다.
따라서 이진분류에 적합한 알고리즘은 시그모이드, 다중분류에 적합한것은 소프트맥스입니다.
박내은
5.1
커널/필터는 어떻게 결정되는지 궁금합니다. 169페이지에 1, 0, 1같이 배열된 숫자들이 어떻게 나오는지 궁금해요.
기존에는 이미지 처리를 위해서 고정된 필터를 사용했고, 이미지를 처리하고 분류하는 알고리즘을 개발할 때 필터링 기법을 사용하여 분류 정확도를 향상시켰습니다. 하지만 이러한 필터링 기법을 사용할때 있어 필터를 사람의 직관이나 반복적인 실험을 통해 최적의 필터를 찾아야했습니다.
따라서 합성곱 신경망은 이러한 필터를 일일이 수동으로 고정된 필터를 찾는 것이 아니라 자동으로 데이터 처리에 적합한 필터를 학습하는 것을 목표로 나오게 되었습니다.
유성현
5.1.2 풀링층 (p.173)
풀링 연산에는 중요한 가중치를 갖는 값의 특성이 희미해질 수 있기 때문에 대부분 최대 풀링을 사용한다고 합니다.
책에서 언급되진 않지만 전역 평균 풀링(Global Average Pooling)이 많이 쓰이는 것으로 아는데 어떤 경우에 사용하는 것인지, 어떤 장점이 있는지 궁금합니다.
전역평균풀링의 장점은 첨부해주신 사이트에 잘 나와있는 것 같습니다. 그걸 참고해주시면 될 것 같습니다.
GAP은 각 샘플의 특성 맵마다 하나의 숫자를 출력합니다. 상당히 파괴적인 방법이죠. 특성 맵의 대부분 정보를 잃지만 효과적으로 노드와 파라미터를 줄여 출력층에는 유용할 수 있습니다. 충분히 특성 맵의 채널 수가 많으면 적용해도 됩니다. 다만 채널 수가 적으면 Flatten이 유리하다고 합니다. 아래의 사이트를 참고해주세요.
https://koreapy.tistory.com/916 Flatten
합성곱 신경망 1
1. 합성곱 신경망
합성곱 신경망(Convolutional Neural Netwark,CNN) : 이미지 전체를 한 번에 계산하는 것이 아닌 이미지의 국소적 부분을 계산함으로써 시간과 자원을 절약하여 이미지의 세밀한 부분까지 분석할 수 있는 신경망.
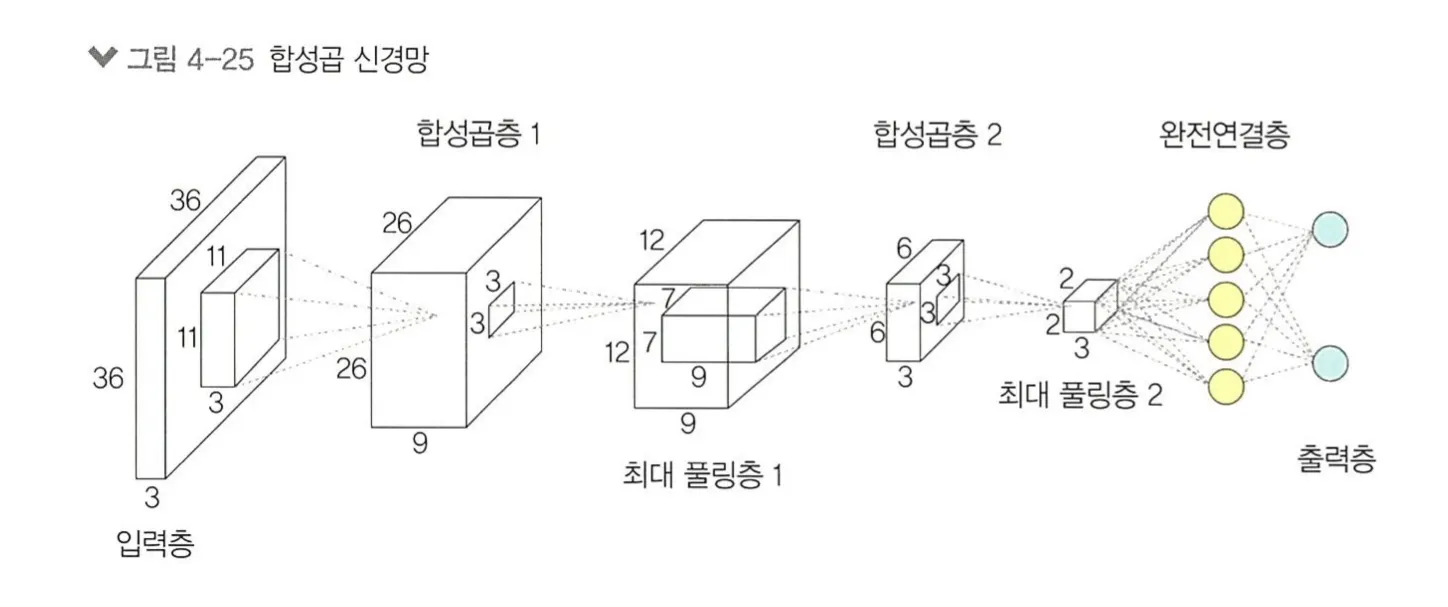
1.1. 합성곱층의 필요성
이미지 분석은 아래 그림처럼 이미지를 1차원 텐서인 벡터로 변환하고 가중치를 매겨 은닉층으로 전달한다.
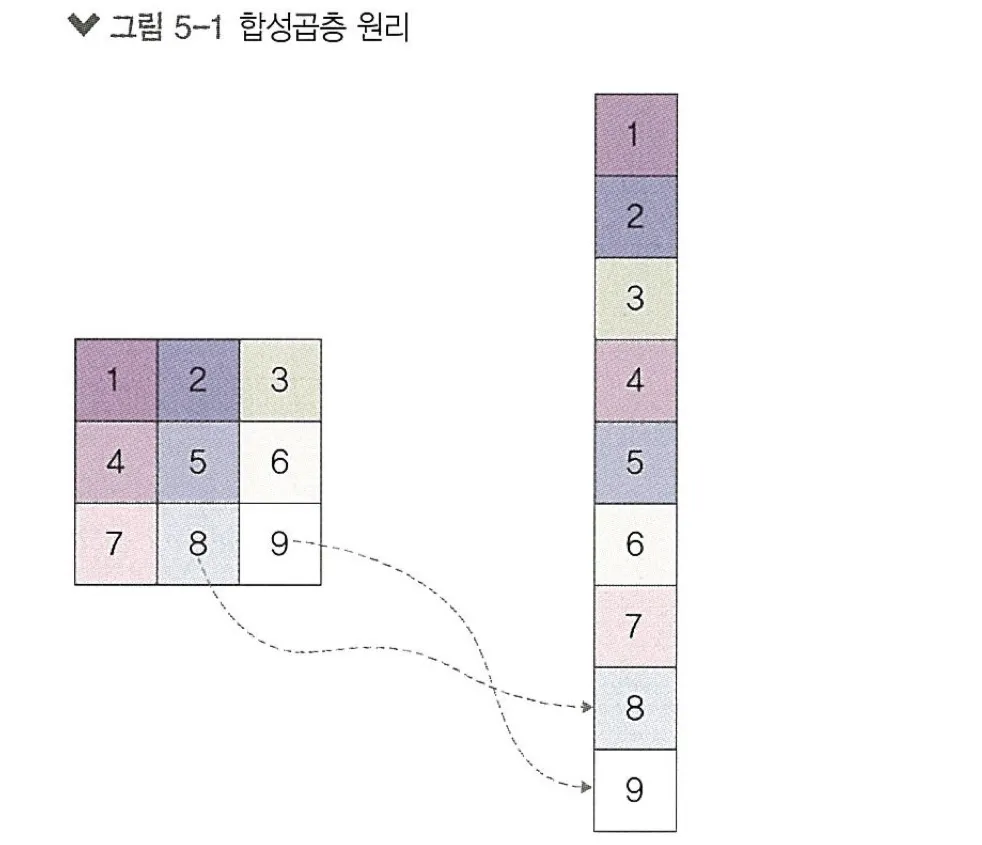
1차원으로 변환된 결과는 사람이 보이게도 기계에도 원래 어떤 이미지였는지 알아보기가 힘들다. 즉 위와 같이 1차원으로 변환하며 공간적인 구조(spatial structure) 정보가 유실된 상태가 된다.
*공간적인 구조 정보 : 거리가 가까운 어떤 픽셀들끼리는 어떤 연관이 있고, 어떤 픽셀들끼리는 값이 비슷하거나 등을 포함하는 정보
결국 이미지의 공간적인 구조 정보를 보존하면서 학습할 수 있는 방법이 필요해졌고, 이를 위해 합성곱 신경망을 사용한다.
1.2. 합성곱 신경망 구조
합성곱 신경망은 음성인식이나 이미지/영상 인식에서 주로 사용되며 크게 다섯개의 개층으로 나누어진다.
입력층
합성곱층
풀링층
완전연결층
출력층
1.3. 1D, 2D, 3D 합성곱
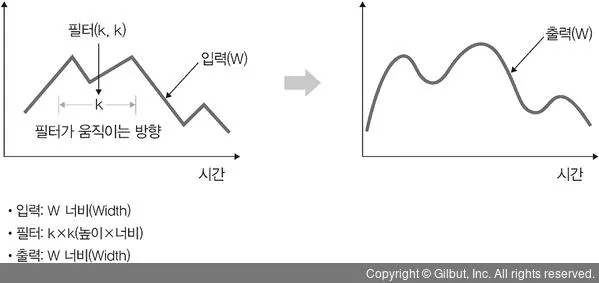
1D 합성곱
1D 합성곱은 필터가 시간을 축으로 좌우로만 이동할 수 있는 합성곱. 입력(W)과 필터(k)에 대한 출력은 W.
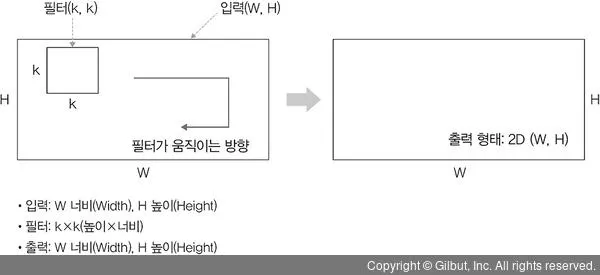
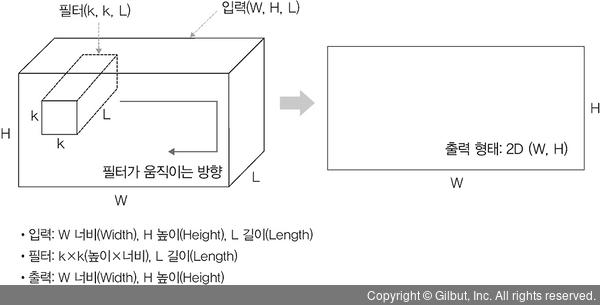
2D 합성곱
2D 합성곱은 필터가 다음 그림과 같이 방향 두 개로 움직이는 형태입니다. 입력(W, H)과 필터(k, k)에 대한 출력은 (W, H)가 되며, 출력 형태는 2D 행렬.
위에서 한거
3D 합성곱
3D 합성곱은 필터가 움직이는 방향이 그림 5-21과 같이 세 개 있습니다. 입력(W, H, L)에 대해 필터(k, k, d)를 적용하면 출력으로 (W, H, L)을 갖는 형태가 3D 합성입니다. 출력은 3D 형태이며, 이때 d < L을 유지하는 것이 중요.

1*1 합성곱
2. 합성곱 신경망 맛보기
데이터셋 확인
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
from torch.autograd import Variable
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import Dataset, DataLoader
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
train_dataset = torchvision.datasets.FashionMNIST("FashionMNIST/", download=True, transform=
transforms.Compose([transforms.ToTensor()]))
test_dataset = torchvision.datasets.FashionMNIST("FashionMNIST/", download=True, train=False, transform=
transforms.Compose([transforms.ToTensor()]))
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=100)
test_loader = torch.utils.data.DataLoader(test_dataset,
batch_size=100)
labels_map = {0 : 'T-Shirt', 1 : 'Trouser', 2 : 'Pullover', 3 : 'Dress', 4 : 'Coat', 5 : 'Sandal', 6 : 'Shirt',
7 : 'Sneaker', 8 : 'Bag', 9 : 'Ankle Boot'}
fig = plt.figure(figsize=(8,8));
columns = 4;
rows = 5;
for i in range(1, columns*rows +1):
img_xy = np.random.randint(len(train_dataset));
img = train_dataset[img_xy][0][0,:,:]
fig.add_subplot(rows, columns, i)
plt.title(labels_map[train_dataset[img_xy][1]])
plt.axis('off')
plt.imshow(img, cmap='gray')
plt.show()
Python
복사

심층 신경망 모델 생성
class FashionDNN(nn.Module):
def __init__(self):
super(FashionDNN,self).__init__()
self.fc1 = nn.Linear(in_features=784,out_features=256)
self.drop = nn.Dropout2d(0.25)
self.fc2 = nn.Linear(in_features=256,out_features=128)
self.fc3 = nn.Linear(in_features=128,out_features=10)
def forward(self,input_data):
out = input_data.view(-1, 784)
out = F.relu(self.fc1(out))
out = self.drop(out)
out = F.relu(self.fc2(out))
out = self.fc3(out)
return out
learning_rate = 0.001;
model = FashionDNN();
model.to(device)
criterion = nn.CrossEntropyLoss();
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate);
print(model)
Python
복사

심층 신경망을 이용한 모델 학습
num_epochs = 5
count = 0
loss_list = []
iteration_list = []
accuracy_list = []
predictions_list = []
labels_list = []
for epoch in range(num_epochs):
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
train = Variable(images.view(100, 1, 28, 28))
labels = Variable(labels)
outputs = model(train)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
count += 1
if not (count % 50):
total = 0
correct = 0
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
labels_list.append(labels)
test = Variable(images.view(100, 1, 28, 28))
outputs = model(test)
predictions = torch.max(outputs, 1)[1].to(device)
predictions_list.append(predictions)
correct += (predictions == labels).sum()
total += len(labels)
accuracy = correct * 100 / total
loss_list.append(loss.data)
iteration_list.append(count)
accuracy_list.append(accuracy)
if not (count % 500):
print("Iteration: {}, Loss: {}, Accuracy: {}%".format(count, loss.data, accuracy))
Python
복사

정확도는 86퍼센트 정도 나온다.
합성곱 네트워크 생성
class FashionCNN(nn.Module):
def __init__(self):
super(FashionCNN, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=32, kernel_size=3, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.layer2 = nn.Sequential(
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.fc1 = nn.Linear(in_features=64*6*6, out_features=600)
self.drop = nn.Dropout2d(0.25)
self.fc2 = nn.Linear(in_features=600, out_features=120)
self.fc3 = nn.Linear(in_features=120, out_features=10)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.view(out.size(0), -1)
out = self.fc1(out)
out = self.drop(out)
out = self.fc2(out)
out = self.fc3(out)
return out
Python
복사
합성곱 네트워크를 위한 파라미터 정의
learning_rate = 0.001;
model = FashionCNN();
model.to(device)
criterion = nn.CrossEntropyLoss();
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate);
print(model)
Python
복사

모델 학습 및 성능 평가
num_epochs = 5
count = 0
loss_list = []
iteration_list = []
accuracy_list = []
predictions_list = []
labels_list = []
for epoch in range(num_epochs):
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
train = Variable(images.view(100, 1, 28, 28))
labels = Variable(labels)
outputs = model(train)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
count += 1
if not (count % 50):
total = 0
correct = 0
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
labels_list.append(labels)
test = Variable(images.view(100, 1, 28, 28))
outputs = model(test)
predictions = torch.max(outputs, 1)[1].to(device)
predictions_list.append(predictions)
correct += (predictions == labels).sum()
total += len(labels)
accuracy = correct * 100 / total
loss_list.append(loss.data)
iteration_list.append(count)
accuracy_list.append(accuracy)
if not (count % 500):
print("Iteration: {}, Loss: {}, Accuracy: {}%".format(count, loss.data, accuracy))
Python
복사

약 90퍼센트의 정확도가 나오며 심층 신경망과 비교하면 더 높다.
3. 전이학습
전이 학습(Transfer Learning) : 특정 분야에서 학습된 신경망의 일부 능력을 유사하거나 전혀 새로운 분야에서 사용되는 신경망의 학습에 이용하는 것을 말한다.

결과적으로 비교적 적은 수의 데이터를 가지고도 우리가 원하는 과제를 해결할 수 있다.
전이학습을 위한 방법으로는 특성 추출과 미세조정기법이 있다.
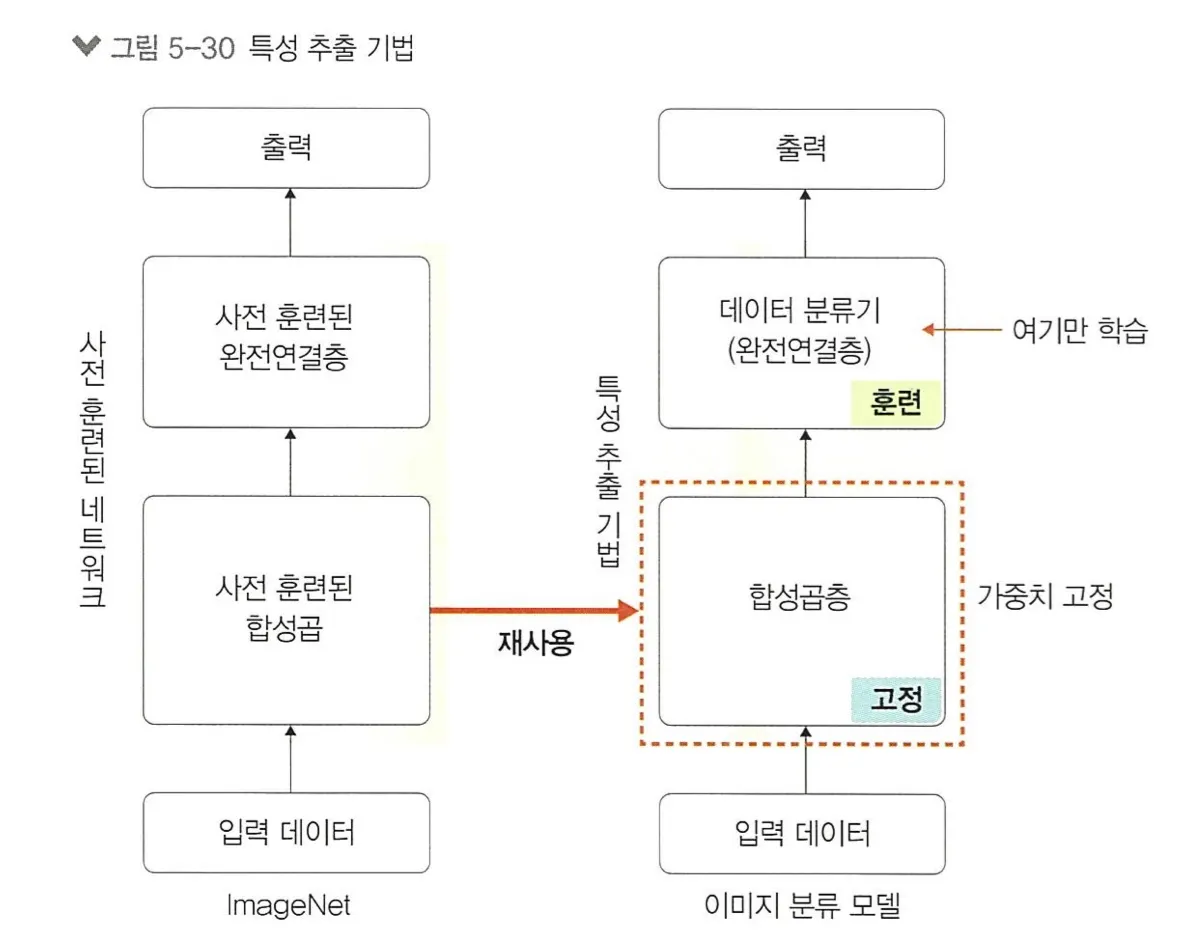
3.1. 특성 추출 기법
특성 추출(feature extractor) : ImageNet 데이터셋으로 사전 훈련된 모델을 가져온 후 마지막에 완전연결층 부분만 새로 만든다. 즉, 학습할 때는 마지막 완전연결층(이미지의 카테고리를 결정하는 부분)만 학습하고 나머지 계층들은 학습되지 않도록 한다.
합성곱층 : 합성곱층과 풀링층
데이터 분류기(완전연결층) : 추출된 특성을 입력받아 최종적으로 이미지에 대한 클래스를 분류하는 부분
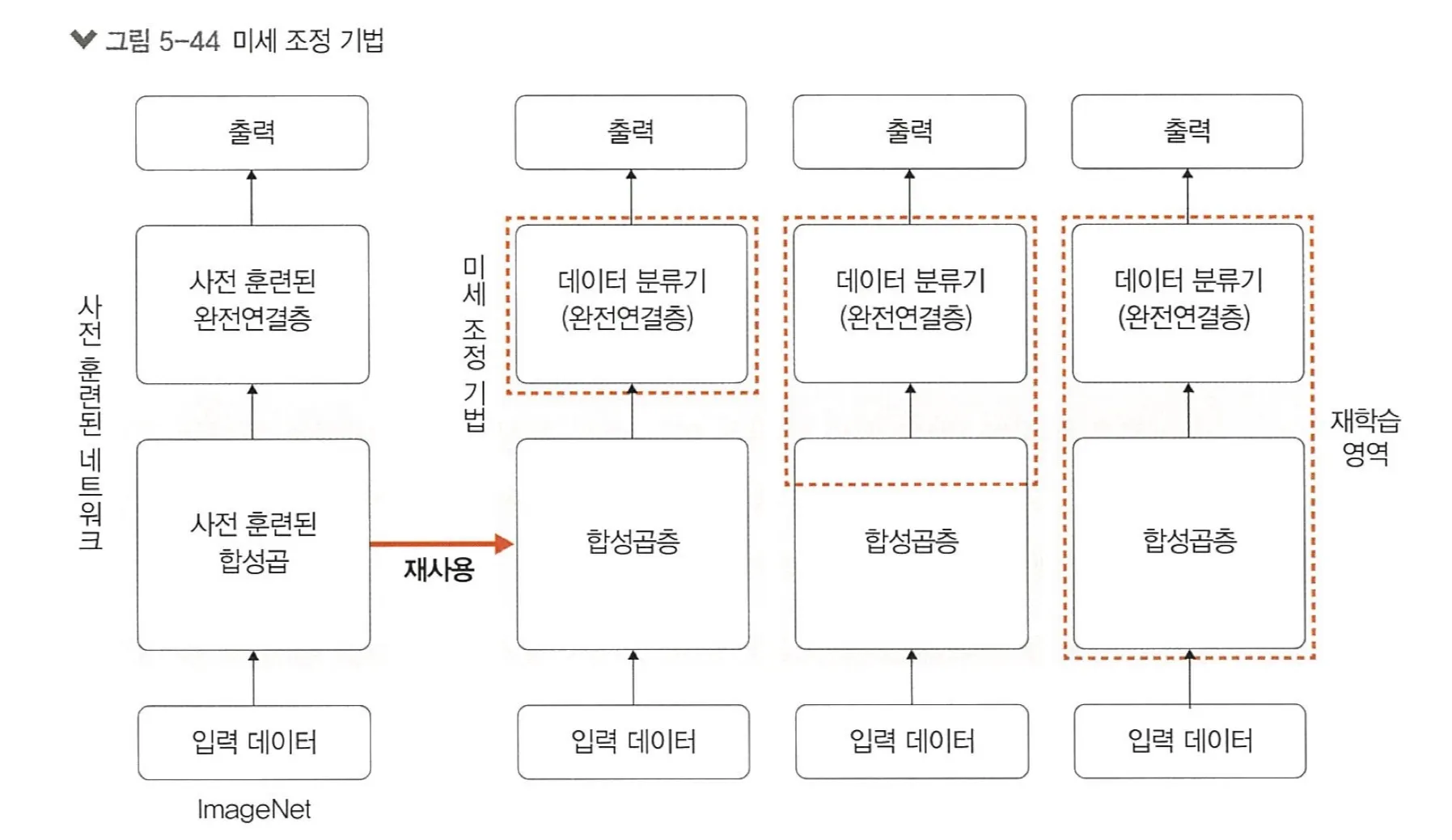
3.2. 미세 조정 기법
미세조정(fine-tuning) 기법 : 특성 추출 기법에서 더 나아가 사전 훈련된 모델과 합성곱층, 데이터 분류기의 가중치를 업데이트하여 훈련시키는 방식이다.
새로운 이미지 데이터를 사용하여 네트워크의 가중치를 업데이트해서 특성을 다시 추출할 수 있다.
훈련덴 모델에 따라 세울 수 있는 전략
•
데이터셋이 크고 사전 훈련된 모델과 유사성이 작을 경우 : 모델 전체를 재학습
•
데이터셋이 크고 사전 훈련된 모델과 유사성이 클 경우 : 합성곱층의 뒷부분과 데이터 분류기를 학습
•
데이터셋이 작고 사전 훈련된 모델과 유사성이 작을 경우 : 합성곱층의 일부분과 데이터 분류기를 학습
•
데이터셋이 작과 사전 훈련된 모델과 유사성이 클 경우 : 데이터 분류기만 학습
4. 설명 가능한 CNN
설명 가능한 CNN : 딥러닝 처리 결과를 사람이 이해할 수 있는 방식으로 제시하는 기술.
CNN이 신뢰받기 위해서는 CNN 처리 과정을 시각화해야할 필요성이 있다.
4.1. 특성 맵 시각화
특정 입력 이미지에 대한 특성 맵을 시각화 한다는 의미는 특성 맵에서 입력 특성을 감지하는 방법을 이해할 수 있도록 돕는다.
아래는 특성맵을 시각화하여 CNN의 내부 구조를 살펴보며 CNN 결과의 신뢰성을 확보하는 과정이다.
import matplotlib.pyplot as plt
from PIL import Image
import cv2
import torch
import torch.nn.functional as F
import torch.nn as nn
from torchvision.transforms import ToTensor
import torchvision
import torchvision.transforms as transforms
import torchvision.models as models
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class XAI(torch.nn.Module):
def __init__(self, num_classes=2):
super(XAI, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Dropout(0.3),
nn.Conv2d(64, 64, kernel_size=3, padding = 1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(64, 128, kernel_size=3, padding = 1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.Dropout(0.4),
nn.Conv2d(128, 128, kernel_size=3, padding = 1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(128, 256, kernel_size=3, padding = 1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Dropout(0.4),
nn.Conv2d(256, 256, kernel_size=3, padding = 1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Dropout(0.4),
nn.Conv2d(256, 256, kernel_size=3, padding = 1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(256, 512, kernel_size=3, padding = 1, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Dropout(0.4),
nn.Conv2d(512, 512, kernel_size=3, padding = 1, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Dropout(0.4),
nn.Conv2d(512, 512, kernel_size=3, padding = 1, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(512, 512, kernel_size=3, padding = 1, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Dropout(0.4),
nn.Conv2d(512, 512, kernel_size=3, padding = 1, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Dropout(0.4),
nn.Conv2d(512, 512, kernel_size=3, padding = 1, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.classifier = nn.Sequential(
nn.Linear(512, 512, bias=False),
nn.Dropout(0.5),
nn.BatchNorm1d(512),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(512, num_classes)
)
def forward(self, x):
x = self.features(x)
x = x.view(-1, 512)
x = self.classifier(x)
return F.log_softmax(x)
model=XAI()
model.cpu() #모델에 입력되는 이미지를 넘파이로 받아오는 부분때문에 CPU를 사용하도록 지정하였습니다
model.eval()
class LayerActivations:
features=[]
def __init__(self, model, layer_num):
self.hook = model[layer_num].register_forward_hook(self.hook_fn)
def hook_fn(self, module, input, output):
output = output
#self.features = output.to(device).detach().numpy()
self.features = output.detach().numpy()
def remove(self):
self.hook.remove()
from google.colab import files # 데이터 불러오기
file_uploaded=files.upload() # chap05/data/cat.jpg 데이터 불러오기
img=cv2.imread("cat.jpg")
plt.imshow(img)
img = cv2.resize(img, (100, 100), interpolation=cv2.INTER_LINEAR)
img = ToTensor()(img).unsqueeze(0)
print(img.shape)
Python
복사

result = LayerActivations(model.features, 0)
model(img)
activations = result.features
fig, axes = plt.subplots(4,4)
fig = plt.figure(figsize=(12, 8))
fig.subplots_adjust(left=0, right=1, bottom=0, top=1, hspace=0.05, wspace=0.05)
for row in range(4):
for column in range(4):
axis = axes[row][column]
axis.get_xaxis().set_ticks([])
axis.get_yaxis().set_ticks([])
axis.imshow(activations[0][row*10+column])
plt.show()
Python
복사
첫번째 계층에서 특성맵을 볼 수 있다.
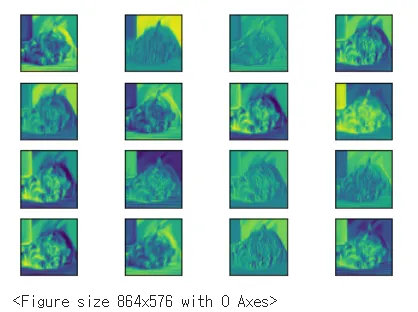
result = LayerActivations(model.features, 20)
으로 만들어 20번째 계층을 출력하면

20번째 특성맵에서는 기존 고양이의 모습을 찾아볼 수 없다.
40번째까지 진행하면
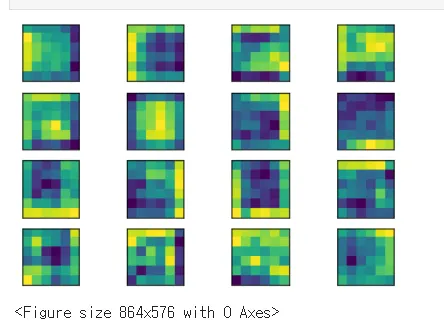
위의 결과를 보면 출력층에 가까울수록 원래 형태를 찾아볼 수 없고 이미지의 특징만이 전달된다.
5. 그래프 합성곱 네트워크
그래프 합성곱 네트워크(graph convolutional network) : 그래프 데이터를 위한 신경망.
5.1. 그래프
그래프(graph) : 방향성이 있거나 없는 에지(간선)로 연결된 노드의 집합.

노드, 정점(node, vertex), 에지(edge) : 간선이라고도 부른다. 정점과 정점 사이를 잇는 선.
5.2 그래프 신경망
그래프 신경망(graph neural network,GNN) : 그래프 구조에서 사용하는 신경망을 의미한다.
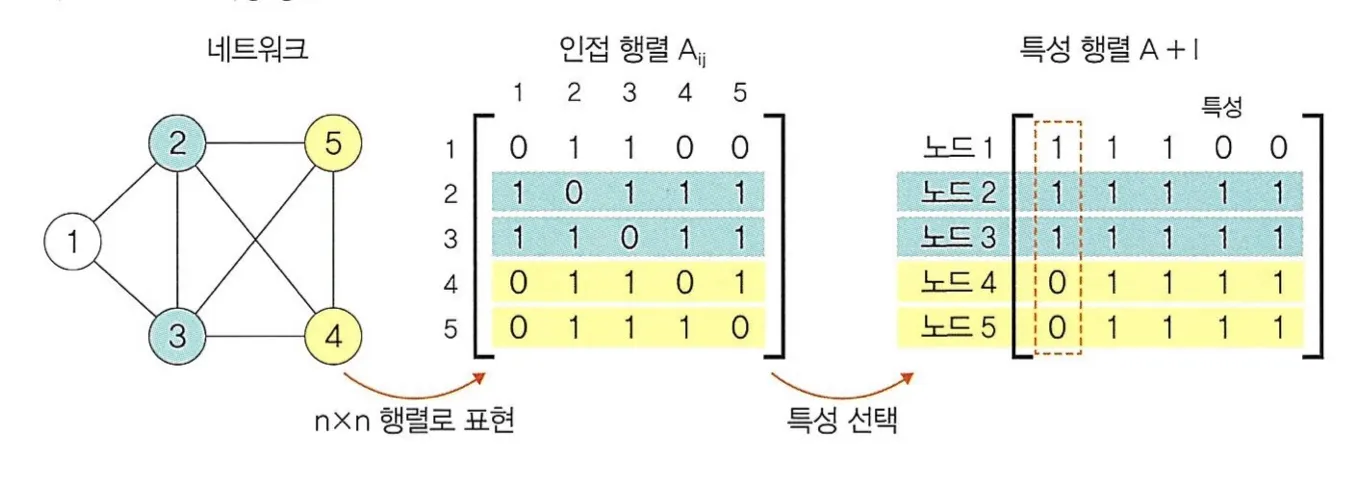
그래프 데이터에 대한 표현은 아래 두 단계로 이루어진다.
1.
인접 행렬 : i와 j의 관련성 여부
2.
특성 행렬 : 인접행렬 + 단위행렬
5.3. 그래프 합성곱 네트워크
그래프 합성곱 네트워크(GCN) : 이미지에 대한 합성곱을 그래프 데이터로 확장한 알고리즘.
리드아웃(readout) : 특성행렬을 하나의 벡터로 변환하는 함수. 즉, 전체 노드의 특성 벡터에 대해 평균을 구하고 그래프 전체를 표현하는 하나의 벡터를 생성한다.
GCN은 SNS에서 관계 네트워크, 학술 연구에서 인용 네트워크, 3D Mesh 와 같은 곳에서 사용된다.