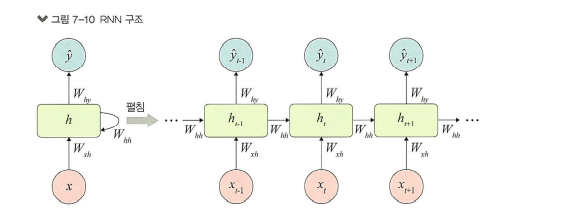
7.4 RNN 구조
RNN : 은닉층 노드들이 연결되어 이전 단계 정보를 은닉층 노드에 저장할 수 있도록 구성한 신경망
xt-1에서 ht-1을 얻고 다음 단계에서 ht-1과 xt를 사용하여 과거 정보와 현재 정보를 모두 반영
RNN의 가중치는 Wxh, Whh, Why로 분류
•
Wxh : 입력층에서 은닉층으로 전달되는 가중치
•
Whh : t 시점의 은닉층에서 t+1 시점의 은닉층으로 전달되는 가중치
•
Why : 은닉층에서 출력층으로 전달되는 가중치
주의 <가중치 Wxh, Whh, Why는 모든 시점에 동일하다>
<t 단계에서의 RNN 계산>
1.은닉층
계산을 위해 xt와 ht-1이 필요합니다. 즉, (이전 은닉층×은닉층 → 은닉층 가중치 + 입력층 → 은닉층 가중치×(현재) 입력 값)으로 계산할 수 있으며, RNN에서 은닉층은 일반적으로 하이퍼볼릭 탄젠트 활성화 함수를 사용
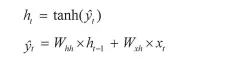
2.출력층
심층 신경망과 계산 방법이 동일합니다. 즉, (은닉층 → 출력층 가중치×현재 은닉층)에 소프트맥스 함수를 적용
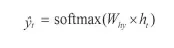
3.RNN의 오차(E)
심층 신경망에서 전방향(feedforward) 학습과 달리 각 단계(t)마다 오차를 측정합니다.
즉, 각 단계마다 실제 값(yt)과 예측 값(y^i)으로 오차(평균 제곱 오차(mean square error) 적용)를 이용하여 측정
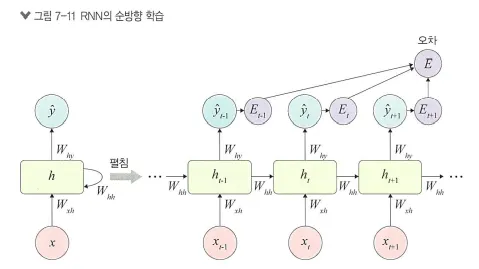
4.RNN에서 역전파
BPTT(BackPropagation Through Time)를 이용하여 모든 단계마다 처음부터 끝까지 역전파
오차는 각 단계(t)마다 오차를 측정하고 이전 단계로 전달되는데, 이것을 BPTT라고 합니다.
즉, 3에서 구한 오차를 이용하여 Wxh, Whh, Why및 바이어스(bias)를 업데이트합니다.
이때 BPTT는 오차가 멀리 전파될 때(왼쪽으로 전파) 계산량이 많아지고 전파되는 양이 점차 적어지는 문제점(기울기 소멸 문제(vanishing gradient problem))이 발생합니다.
기울기 소멸 문제를 보완하기 위해 오차를 몇 단계까지만 전파시키는 생략된-BPTT(truncated BPTT)를 사용할 수도 있고, 근본적으로는 LSTM 및 GRU를 많이 사용

7.4.1 RNN 셀 구현
# 코드 7-3 라이브러리 호출
import torch
import torchtext
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
import time
# 코드 7-4 데이터 전처리
start = time.time()
TEXT = torchtext.legacy.data.Field(lower=True, fix_length=200, batch_first=False) # ------ ①
LABEL = torchtext.legacy.data.Field(sequential=False) # ------ ②
# 코드 7-5 데이터셋 준비
from torchtext.legacy import datasets
train_data, test_data = datasets.IMDB.splits(TEXT, LABEL) # ------ ①
# 코드 7-6 훈련 데이터셋 내용 확인
print(vars(train_data.examples[0]))
Python
복사

데이터는 text와 label을 갖는 사전 형식(dict type)으로 구성
# 코드 7-7 데이터셋 전처리 적용
import string
for example in train_data.examples:
text = [x.lower() for x in vars(example)['text']] # ------ 소문자로 변경
text = [x.replace("<br","") for x in text] # ------ “<br”을 “ ”(공백)으로 변경
text = [''.join(c for c in s if c not in string.punctuation) for s in text] # ------ 구두점 제거
text = [s for s in text if s] # ------ 공백 제거
vars(example)['text'] = text
# 코드 7-8 훈련과 검증 데이터셋 분리
import random
train_data, valid_data = train_data.split(random_state=random.seed(0), split_ratio=0.8) # ------ ①
# 코드 7-9 데이터셋 개수 확인
print(f'Number of training examples: {len(train_data)}')
print(f'Number of validation examples: {len(valid_data)}')
print(f'Number of testing examples: {len(test_data)}')
Python
복사
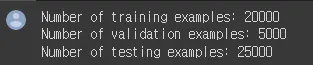
훈련 데이터셋은 2만 개, 검증 데이터셋은 5000개, 테스트 데이터셋은 2만 5000개
# 코드 7-10 단어 집합 만들기
TEXT.build_vocab(train_data, max_size=10000, min_freq=10, vectors=None) # ------ ①
LABEL.build_vocab(train_data)
print(f"Unique tokens in TEXT vocabulary: {len(TEXT.vocab)}")
print(f"Unique tokens in LABEL vocabulary: {len(LABEL.vocab)}")
# 코드 7-11 테스트 데이터셋의 단어 집합 확인
print(LABEL.vocab.stoi)
Python
복사


TEXT는 10002개, LABEL은 세 개의 단어로 구성
pos(positive)(긍정), neg(negative)(부정) 외에 <unk>, 일반적으로 <unk>는 사전에 없는 단어
# 코드 7-12 데이터셋 메모리로 가져오기
BATCH_SIZE = 64
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
embeding_dim = 100 # ------ 각 단어를 100차원으로 조정(임베딩 계층을 통과한 후 각 벡터의 크기)
hidden_size = 300 # ------ ①
train_iterator, valid_iterator, test_iterator = torchtext.legacy.data.BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size=BATCH_SIZE,
device=device) # ------ ②
# 코드 7-13 워드 임베딩 및 RNN 셀 정의
class RNNCell_Encoder(nn.Module):
def __init__(self, input_dim, hidden_size):
super(RNNCell_Encoder, self).__init__()
self.rnn = nn.RNNCell(input_dim, hidden_size) # ------ ①
def forward(self, inputs): # ------ inputs는 입력 시퀀스로 (시퀀스 길이, 배치, 임베딩(seq,batch, embedding))의 형태를 갖습니다.
bz = inputs.shape[1] # ------ 배치를 가져옵니다.
ht = torch.zeros((bz, hidden_size)).to(device) # ------ 배치와 은닉층 뉴런의 크기를 0으로 초기화
for word in inputs:
ht = self.rnn(word, ht) # ------ ②
return ht
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.em = nn.Embedding(len(TEXT.vocab.stoi), embeding_dim) # ------ ③
self.rnn = RNNCell_Encoder(embeding_dim, hidden_size)
self.fc1 = nn.Linear(hidden_size, 256)
self.fc2 = nn.Linear(256, 3)
def forward(self, x):
x = self.em(x)
x = self.rnn(x)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
# 코드 7-14 옵티마이저와 손실 함수 정의
model = Net() # ------ model이라는 이름으로 모델을 객체화
model.to(device)
loss_fn = nn.CrossEntropyLoss() # ------ ①
optimizer = torch.optim.Adam(model.parameters(), lr=0.0001)
# 코드 7-15 모델 학습을 위한 함수 정의
def training(epoch, model, trainloader, validloader):
correct = 0
total = 0
running_loss = 0
model.train()
for b in trainloader:
x, y = b.text, b.label # ------ trainloader에서 text와 label을 꺼내 옵니다.
x, y = x.to(device), y.to(device) # ------ 꺼내 온 데이터가 CPU를 사용할 수 있도록 장치 지정, 반드시 모델과 같은 장치를 사용하도록 지정해야 합니다.
y_pred = model(x)
loss = loss_fn(y_pred, y) # ------ CrossEntropyLoss 손실 함수를 이용하여 오차 계산
optimizer.zero_grad()
loss.backward()
optimizer.step()
with torch.no_grad():
y_pred = torch.argmax(y_pred, dim=1)
correct += (y_pred == y).sum().item()
total += y.size(0)
running_loss += loss.item()
epoch_loss = running_loss / len(trainloader.dataset) # ------ 누적된 오차를 전체 데이터셋으로 나누어서 에포크 단계마다 오차를 구합니다.
epoch_acc = correct / total
valid_correct = 0
valid_total = 0
valid_running_loss = 0
model.eval()
with torch.no_grad():
for b in validloader:
x, y = b.text, b.label
x, y = x.to(device), y.to(device)
y_pred = model(x)
loss = loss_fn(y_pred, y)
y_pred = torch.argmax(y_pred, dim=1)
valid_correct += (y_pred == y).sum().item()
valid_total += y.size(0)
valid_running_loss += loss.item()
epoch_valid_loss = valid_running_loss / len(validloader.dataset)
epoch_valid_acc = valid_correct / valid_total
print('epoch: ', epoch,
'loss: ', round(epoch_loss, 3),
'accuracy:', round(epoch_acc, 3),
'valid_loss: ', round(epoch_valid_loss, 3),
'valid_accuracy:', round(epoch_valid_acc, 3)
) # ------ 훈련이 진행될 때 에포크마다 정확도와 오차(loss)를 출력
return epoch_loss, epoch_acc, epoch_valid_loss, epoch_valid_acc
# 코드 7-16 모델 학습
epochs = 5
train_loss = []
train_acc = []
valid_loss = []
valid_acc = []
for epoch in range(epochs):
epoch_loss, epoch_acc, epoch_valid_loss, epoch_valid_acc = training(epoch, model, train_iterator, valid_iterator)
train_loss.append(epoch_loss) # ------ 훈련 데이터셋을 모델에 적용했을 때의 오차
train_acc.append(epoch_acc) # ------ 훈련 데이터셋을 모델에 적용했을 때의 정확도
valid_loss.append(epoch_valid_loss) # ------ 검증 데이터셋을 모델에 적용했을 때의 오차
valid_acc.append(epoch_valid_acc) # ------ 검증 데이터셋을 모델에 적용했을 때의 정확도
end = time.time()
print(end-start)
Python
복사

에포크를 5로 지정했기 때문에 정확도가 낮지만 학습과 검증 데이터셋에 대한 오차가 유사
# TEST셋에서
# 코드 7-17 모델 예측 함수 정의
def evaluate(epoch, model, testloader):
test_correct = 0
test_total = 0
test_running_loss = 0
model.eval()
with torch.no_grad():
for b in testloader:
x, y = b.text, b.label
x, y = x.to(device), y.to(device)
y_pred = model(x)
loss = loss_fn(y_pred, y)
y_pred = torch.argmax(y_pred, dim=1)
test_correct += (y_pred == y).sum().item()
test_total += y.size(0)
test_running_loss += loss.item()
epoch_test_loss = test_running_loss / len(testloader.dataset)
epoch_test_acc = test_correct / test_total
print('epoch: ', epoch,
'test_loss: ', round(epoch_test_loss, 3),
'test_accuracy:', round(epoch_test_acc, 3)
)
return epoch_test_loss, epoch_test_acc
# 코드 7-18 모델 예측 결과 확인
epochs = 5
test_loss = []
test_acc = []
for epoch in range(epochs):
epoch_test_loss, epoch_test_acc = evaluate(epoch, model, test_iterator)
test_loss.append(epoch_test_loss)
test_acc.append(epoch_test_acc)
end = time.time()
print(end-start)
Python
복사
7.4.2 RNN 계층 구현
# 코드 7-19 라이브러리 호출
import torch
import torchtext
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
import time
# 코드 7-20 데이터셋 내려받기 및 전처리
start = time.time()
TEXT = torchtext.legacy.data.Field(sequential=True, batch_first=True, lower=True)
LABEL = torchtext.legacy.data.Field(sequential=False, batch_first=True)
from torchtext.legacy import datasets
train_data, test_data = datasets.IMDB.splits(TEXT, LABEL) # ------ 역시 IMDB를 사용합니다.
train_data, valid_data = train_data.split(split_ratio=0.8)
TEXT.build_vocab(train_data, max_size=10000, min_freq=10, vectors=None)
LABEL.build_vocab(train_data)
BATCH_SIZE = 100
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# BucketIterator()를 이용하여 훈련, 검증, 테스트 데이터셋으로 분리
# 코드 7-21 데이터셋 분리
train_iterator, valid_iterator, test_iterator = torchtext.legacy.data.BucketIterator.splits((train_data, valid_data, test_data), batch_size=BATCH_SIZE, device=device)
# 코드 7-22 변수 값 지정
vocab_size = len(TEXT.vocab)
n_classes = 2 # ------ pos(긍정), neg(부정)
# 코드 7-23 RNN 계층 네트워크 -> RNN 계층 네트워크 정의
class BasicRNN(nn.Module):
def __init__(self, n_layers, hidden_dim, n_vocab, embed_dim, n_classes, dropout_p=0.2):
super(BasicRNN, self).__init__()
self.n_layers = n_layers # ------ RNN 계층에 대한 개수
self.embed = nn.Embedding(n_vocab, embed_dim) # ------ 워드 임베딩 적용
self.hidden_dim = hidden_dim
self.dropout = nn.Dropout(dropout_p) # ------ 드롭아웃 적용
self.rnn = nn.RNN(embed_dim, self.hidden_dim, num_layers=self.n_layers, batch_first=True) # ------ ①
self.out = nn.Linear(self.hidden_dim, n_classes)
def forward(self, x):
x = self.embed(x) # ------ 문자를 숫자/벡터로 변환
h_0 = self._init_state(batch_size=x.size(0)) # ------ 최초 은닉 상태의 값을 0으로 초기화
x, _ = self.rnn(x, h_0) # ------ RNN 계층을 의미하며, 파라미터로 입력과 이전 은닉 상태의 값을 받습니다.
h_t = x[:, -1, :] # ------ 모든 네트워크를 거쳐서 가장 마지막에 나온 단어의 임베딩 값(마지막 은닉 상태의 값)
self.dropout(h_t)
logit = torch.sigmoid(self.out(h_t))
return logit
def _init_state(self, batch_size=1):
weight = next(self.parameters()).data # ------ 모델의 파라미터 값을 가져와서 weight 변수에 저장
return weight.new(self.n_layers, batch_size, self.hidden_dim).zero_() # ------ 크기가 (계층의 개수, 배치 크기, 은닉층의 뉴런/유닛 개수)인 은닉 상태(텐서)를 생성하여 0으로 초기화한 후 반환
# 코드 7-24 손실 함수와 옵티마이저 설정
model = BasicRNN(n_layers=1, hidden_dim=256, n_vocab=vocab_size, embed_dim=128, n_classes=n_classes, dropout_p=0.5)
model.to(device)
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.0001)
# 코드 7-25 모델 학습 함수
def train(model, optimizer, train_iter):
model.train()
for b, batch in enumerate(train_iter):
x, y = batch.text.to(device), batch.label.to(device)
y.data.sub_(1) # ------ ①
optimizer.zero_grad()
logit = model(x)
loss = F.cross_entropy(logit, y)
loss.backward()
optimizer.step()
if b % 50 == 0: # ------ 훈련 데이터셋의 개수를 50으로 나누어서 나머지가 0이면 출력
print("Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}".format(e,b *
len(x),len(train_iter.dataset),loss.item()))
# 코드 7-26 모델 평가 함수
def evaluate(model, val_iter):
model.eval()
corrects, total, total_loss = 0, 0, 0
for batch in val_iter:
x, y = batch.text.to(device), batch.label.to(device)
y.data.sub_(1)
logit = model(x)
loss = F.cross_entropy(logit, y, reduction="sum")
total += y.size(0)
total_loss += loss.item()
corrects += (logit.max(1)[1].view(y.size()).data == y.data).sum() # ------ ①
avg_loss = total_loss / len(val_iter.dataset)
avg_accuracy = corrects / total
return avg_loss, avg_accuracy
# 코드 7-27 모델 학습 및 평가
BATCH_SIZE = 100
LR = 0.001
EPOCHS = 5
for e in range(1, EPOCHS + 1):
train(model, optimizer, train_iterator)
val_loss, val_accuracy = evaluate(model, valid_iterator)
print("[EPOCH: %d], Validation Loss: %5.2f | Validation Accuracy: %5.2f" % (e, val_loss, val_accuracy))
Python
복사
7.5 LSTM
RNN은 결정적 단점 : 가중치가 업데이트되는 과정에서 기울기가 1보다 작은 값이 계속 곱해지기 때문에 기울기가 사라지는 기울기 소멸 문제가 발생
이를 해결하기 위해 LSTM이나 GRU 같은 확장된 RNN 방식들을 사용
< LSTM 구조>
•
LSTM 순전파
LSTM은 기울기 소멸 문제를 해결하기 위해 망각 게이트, 입력 게이트, 출력 게이트라는 새로운 요소를 은닉층의 각 뉴런에 추가
1. 망각 게이트(forget gate)
과거 정보를 어느 정도 기억할지 결정
과거 정보와 현재 데이터를 입력받아 시그모이드를 취한 후 그 값을 과거 정보에 곱해 줍니다.
따라서 시그모이드의 출력이 0이면 과거 정보는 버리고, 1이면 과거 정보는 온전히 보존
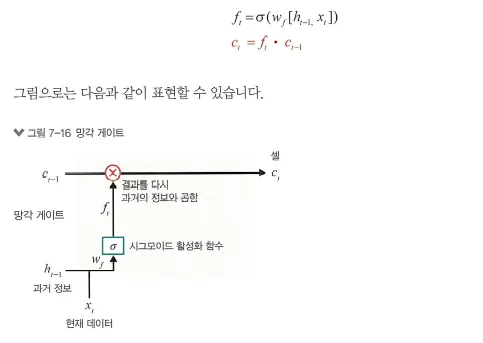
•
계산 값이 1이면 바로 직전의 정보 메모리에 유지
•
계산 값이 0이면 초기화
2. 입력 게이트(input gate)
현재 정보를 기억하기 위해 만듦
과거 정보와 현재 데이터를 입력받아 시그모이드와 하이퍼볼릭 탄젠트 함수를 기반으로 현재 정보에 대한 보존량을 결정
즉, 현재 메모리에 새로운 정보를 반영할지 결정
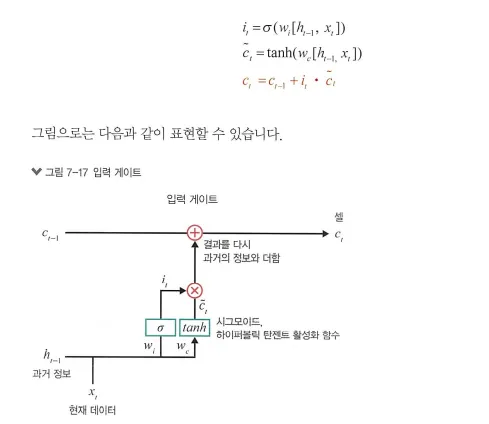
•
계산한 값이 1이면 입력 xt가 들어올 수 있도록 허용(open)
•
계산한 값이 0이면 차단
3. 셀
각 단계에 대한 은닉 노드(hidden node)를 메모리 셀이라고 함
‘총합(sum)’을 사용하여 셀 값을 반영하며, 이것으로 기울기 소멸 문제가 해결
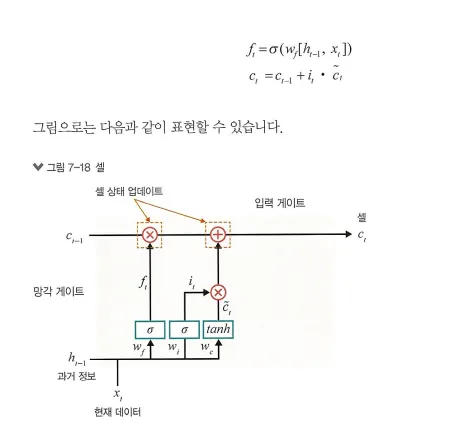
망각 게이트와 입력 게이트의 이전 단계 셀 정보를 계산하여 현재 단계의 셀 상태(cell state)를 업데이트
4. 출력 게이트(output gate)
과거 정보와 현재 데이터를 사용하여 뉴런의 출력을 결정
이전 은닉 상태(hidden state)와 t번째 입력을 고려해서 다음 은닉 상태를 계산합니다.
그리고 LSTM에서는 이 은닉 상태가 그 시점에서의 출력
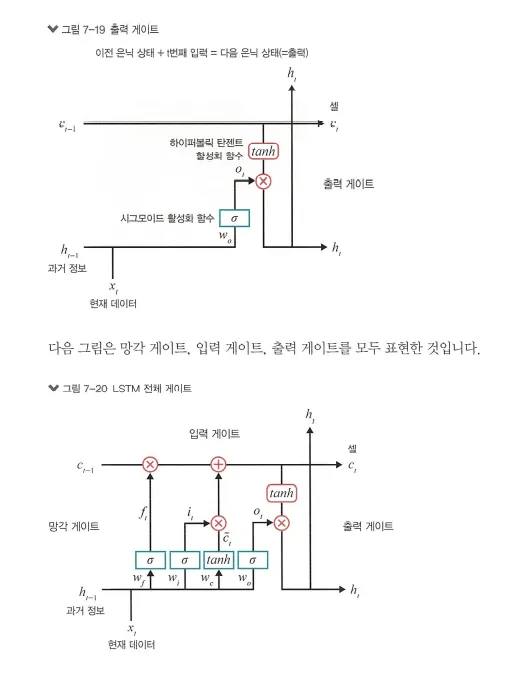
출력 게이트는 갱신된 메모리의 출력 값을 제어하는 역할
•
계산한 값이 1이면 의미 있는 결과로 최종 출력
•
계산한 값이 0이면 해당 연산 출력을 하지 않음
•
LSTM 역전파
LSTM은 셀을 통해서 역전파를 수행하기 때문에 ‘중단 없는 기울기(uninterrupted gradient f low)’라고도 합
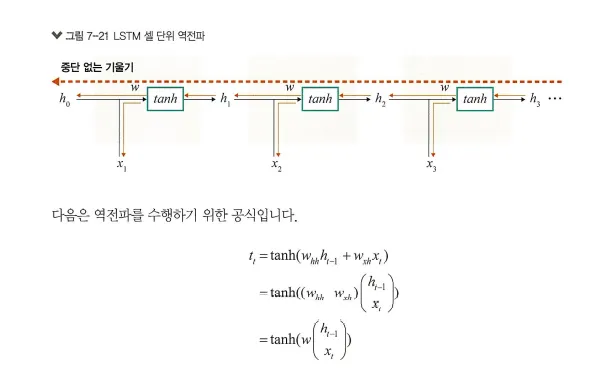
즉, 다음 그림과 같이 최종 오차는 모든 노드에 전파되는데, 이때 셀을 통해서 중단 없이 전파
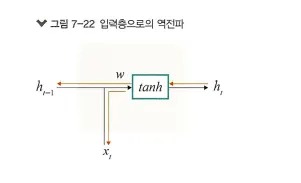
셀 내부적으로는 오차가 입력(xt)으로 전파
# 코드 7-29 라이브러리 호출
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision.datasets as dataset
from torch.autograd import Variable
from torch.nn import Parameter # 파라미터 목록을 가지고 있는 라이브러리
from torch import Tensor
import torch.nn.functional as F
from torch.utils.data import DataLoader
import math # 수학과 관련되어 다양한 함수들과 상수들이 정의되어 있는 라이브러리
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
cuda = True if torch.cuda.is_available() else False # GPU 사용에 필요
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
torch.manual_seed(125)
if torch.cuda.is_available():
torch.cuda.manual_seed_all(125)
# 코드 7-30 데이터 전처리
import torchvision.transforms as transforms
mnist_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (1.0,)) # 평균을 0.5, 표준편차를 1.0으로 데이터 정규화
])
# 코드 7-31 데이터셋 내려받기
from torchvision.datasets import MNIST
download_root = '../chap07/MNIST_DATASET' # ------ MNIST를 내려받을 경로
train_dataset = MNIST(download_root, transform=mnist_transform, train=True, download=True) ------ ①
valid_dataset = MNIST(download_root, transform=mnist_transform, train=False, download=True)
test_dataset = MNIST(download_root, transform=mnist_transform, train=False, download=True)
# 코드 7-32 데이터셋을 메모리로 가져오기
batch_size = 64
train_loader = DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
valid_loader = DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=True)
test_loader = DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=True)
# 코드 7-33 변수 값 지정
# 배치 크기 및 에포크 등 변수에 대한 값을 지정
batch_size = 100
n_iters = 6000
num_epochs = n_iters / (len(train_dataset) / batch_size)
num_epochs = int(num_epochs)
# 코드 7-34 LSTM 셀 네트워크 구축
class LSTMCell(nn.Module): # ------ LSTM 셀에 대한 더 자세한 설명을 원한다면 http://www.bioinf.jku.at/publications/older/2604.pdf 논문을 참고하세요.
def __init__(self, input_size, hidden_size, bias=True):
super(LSTMCell, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.bias = bias
self.x2h = nn.Linear(input_size, 4 * hidden_size, bias=bias) # ------ ①
self.h2h = nn.Linear(hidden_size, 4 * hidden_size, bias=bias) # ------ ①′
self.reset_parameters()
def reset_parameters(self): # ------ 모델의 파라미터 초기화
std = 1.0 / math.sqrt(self.hidden_size)
for w in self.parameters():
w.data.uniform_(-std, std) # ------ ②
def forward(self, x, hidden):
hx, cx = hidden
x = x.view(-1, x.size(1))
gates = self.x2h(x) + self.h2h(hx) # ------ ①″
gates = gates.squeeze() # ------ ③
ingate, forgetgate, cellgate, outgate = gates.chunk(4, 1) # ------ ①‴
ingate = F.sigmoid(ingate) # ------ 입력 게이트에 시그모이드 활성화 함수 적용
forgetgate = F.sigmoid(forgetgate) # ------ 망각 게이트에 시그모이드 활성화 함수 적용
cellgate = F.tanh(cellgate) # ------ 셀 게이트에 탄젠트 활성화 함수 적용
outgate = F.sigmoid(outgate) # ------ 출력 게이트에 시그모이드 활성화 함수 적용
cy = torch.mul(cx, forgetgate) + torch.mul(ingate, cellgate) # ------ ④
hy = torch.mul(outgate, F.tanh(cy)) # ------ ④′
return(hy, cy)
# 코드 7-35 LSTM 셀의 전반적인 네트워크
class LSTMModel(nn.Module):
def __init__(self, input_dim, hidden_dim, layer_dim, output_dim, bias=True):
super(LSTMModel, self).__init__()
self.hidden_dim = hidden_dim # ------ 은닉층의 뉴런/유닛 개수
self.layer_dim = layer_dim
self.lstm = LSTMCell(input_dim, hidden_dim, layer_dim) # ------ ①
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
if torch.cuda.is_available(): # ------ GPU 사용 유무 확인
h0 = Variable(torch.zeros(self.layer_dim, x.size(0), self.hidden_dim).cuda()) ------(은닉층의 계층 개수, 배치 크기, 은닉층의 뉴런 개수) 형태를 갖는 은닉 상태를 0으로 초기화
else:
h0 = Variable(torch.zeros(self.layer_dim, x.size(0), self.hidden_dim))
if torch.cuda.is_available(): # ------ GPU 사용 유무 확인
c0 = Variable(torch.zeros(self.layer_dim, x.size(0), self.hidden_dim).cuda()) ------ (은닉층의 계층 개수, 배치 크기, 은닉층의 뉴런 개수) 형태를 갖는 셀 상태를 0으로 초기화
else:
c0 = Variable(torch.zeros(self.layer_dim, x.size(0), hidden_dim))
outs = []
cn = c0[0,:,:] # ------ (은닉층의 계층 개수, 배치 크기, 은닉층의 뉴런 개수) 크기를 갖는 셀 상태에 대한 텐서
hn = h0[0,:,:] # ------ (은닉층의 계층 개수, 배치 크기, 은닉층의 뉴런 개수) 크기를 갖는 은닉 상태에 대한 텐서
for seq in range(x.size(1)): # ------ LSTM 셀 계층을 반복하여 쌓아 올립니다.
hn, cn = self.lstm(x[:,seq,:], (hn,cn)) # ------ 은닉 상태(hn)와 셀 상태를 LSTMCell에 적용한 결과를 또다시 hn, cn에 저장
outs.append(hn)
out = outs[-1].squeeze()
out = self.fc(out)
return out
# 코드 7-36 옵티마이저와 손실 함수 지정
input_dim = 28
hidden_dim = 128
layer_dim = 1
output_dim = 10
model = LSTMModel(input_dim, hidden_dim, layer_dim, output_dim)
if torch.cuda.is_available(): # ------ GPU 사용 유무 확인
model.cuda()
criterion = nn.CrossEntropyLoss()
learning_rate = 0.1
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
# 코드 7-37 모델 학습 및 성능 확인
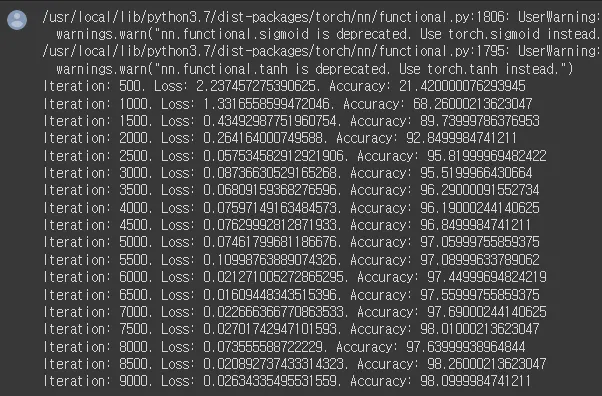
seq_dim = 28
loss_list = []
iter = 0
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader): # ------ 훈련 데이터셋을 이용한 모델 학습
if torch.cuda.is_available(): ------ GPU 사용 유무 확인
images = Variable(images.view(-1, seq_dim, input_dim).cuda()) # ------ ①
labels = Variable(labels.cuda())
else: # ------ GPU를 사용하지 않기 때문에 else 구문이 실행
images = Variable(images.view(-1, seq_dim, input_dim))
labels = Variable(labels)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels) # ------ 손실 함수를 이용하여 오차 계산
if torch.cuda.is_available():
loss.cuda()
loss.backward()
optimizer.step() # ------ 파라미터 업데이트
loss_list.append(loss.item())
iter += 1
if iter % 500 == 0: # ------ 정확도(accuracy) 계산
correct = 0
total = 0
for images, labels in valid_loader: # ------ 검증 데이터셋을 이용한 모델 성능 검증
if torch.cuda.is_available():
images = Variable(images.view(-1, seq_dim, input_dim).cuda())
else:
images = Variable(images.view(-1, seq_dim, input_dim))
outputs = model(images)
_, predicted = torch.max(outputs.data, 1) # ------ 모델을 통과한 결과의 최댓값으로부터 예측 결과 가져오기
total += labels.size(0) # ------ 총 레이블 수
if torch.cuda.is_available():
correct += (predicted.cpu() == labels.cpu()).sum()
else:
correct += (predicted == labels).sum()
accuracy = 100 * correct / total
print('Iteration: {}. Loss: {}. Accuracy: {}'.format(iter, loss.item(), accuracy))
Python
복사