발표 자료
질문
*이름 적고 질문 적어 주세요

황현수
<미니 배치 경사 하강법 파이토치에서 구현하기>
첫 줄 클래스 생성할 때 class CustomDataser(Dataset):
괄호 안에 Dataset이 왜 있는지 모르겠어요

import torch
class CustomDataset:
def __init__(self):
self.x_data = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
self.y_data = [[12], [18], [11]]
def __len__(self):
return len(self.x_data)
def __getitem__(self, idx):
x = torch.FloatTensor(self.x_data[idx])
y = torch.FloatTensor(self.y_data[idx])
return x, y
def __str__(self):
return "x: {}, y: {} ".format(self.x_data, self.y_data)
dataset = CustomDataset() # 객체생성, __init__ 메소드 호출
print(dataset) # __str__ 메소드 호출
len(dataset) # __len__ 메소드 호출
dataset[0] # __getitem__ 메소드 호출
dataset[1] # __getitem__ 메소드 호출
dataset[2] # __getitem__ 메소드 호출
Python
복사
## 상속을 하면 자식 클래스가 부모 클래스의 변수와 메소드를 그대로 물려받는다
class Employee:
"""직원 클래스"""
company_name = '버거킹' # 가게 이름
raise_percentage = 1.03 # 시급 인상률
def __init__(self, name, wage):
"""인스턴스 변수 설정"""
self.name = name # 이름
self.wage = wage # 시급
def raise_pay(self):
"""시급을 인상하는 메소드"""
self.wage *= self.raise_percentage
def __str__(self):
"""직원 정보를 문자열로 리턴하는 메소드"""
return Employee.company_name + " 직원: " + self.name
class Cashier(Employee): # Employee 클래스 상속
pass
hyeonsu = Cashier("황현수", 8900) # 객체 생성
hyeonsu.raise_pay()
print(hyeonsu.wage)
print(hyeonsu) # __str__ 메소드 출력
# help 함수 : Class의 정보를 자세히 출력 -> Employee(부모) 클래스의 변수와 메소드 가지고 있음
help(Cashier)
# Method resolution order: -> Cashier 클래스의 상속 관계 보여줌
# Cashier
# Employee -> Cashier Class의 부모 Class
# builtins.object -> Employee Class의 부모 Class : 파이썬에서 모든 Class는 자동으로 builtins.object Class를 상속받음
# issubclass 함수 : 한 클래스가 다른 클래스의 자식 클래스인지를 알려주는 함수
print(issubclass(Cashier, Employee)) # 출력: True
## 부모 클래스로부터 물려 받은 내용을 자식 클래스가 자신에 맞게 변경 -> 오버라이딩(덮어쓴다)
# 오버라이딩 -> 부모 클래스에서 물려받은 메소드와 같은 이름의 메소드를 내용을 바꿔 정의
## __init__ 메소드 오버라이딩(number_sold 변수 추가)
class Cashier(Employee): # Employee 클래스 상속
def __init__(self, name, wage, number_sold): # number_sold 변수 추가(오버라이딩)
self.name = name # 이름
self.wage = wage # 시급
self.number_sold = number_sold # 하루 판매량
# 똑같은 name, wage 가져오기
class Cashier(Employee):
def __init__(self, name, wage, number_sold):
Employee.__init__(self, name, wage) # 부모클래스 Employee를 통해 init메소드 호출
self.number_sold = number_sold
# super()함수로 더 간단하게 -> 부모 클래스의 메소드를 호출 가능
class Cashier(Employee):
def __init__(self, name, wage, number_sold):
super().__init__(name, wage) # 자식 클래스에서 부모클래스의 메소드를 사용하고 싶을 때 사용하는 함수, self파라미터 쓸 필요 없다
self.number_sold = number_sold #
class DeliveryMan(Employee): # Employee 클래스 상속
pass
hyeon = Cashier("황현수", 8900, 4) # 객체 생성(오버라이딩 된)
hyeon.raise_pay()
print(Cashier.raise_percentage)
print(Cashier.company_name)
print(hyeon.name)
print(hyeon.wage)
print(hyeon.number_sold)
## __str__ 메소드 오버라이딩 (부모클래스 직원을 자식클래스에서 계산대 직원으로 수정)
class Cashier(Employee):
def __init__(self, name, wage, number_sold):
super().__init__(name, wage) # 자식 클래스에서 부모클래스의 메소드를 사용하고 싶을 때 사용하는 함수, self파라미터 쓸 필요 없다
self.number_sold = number_sold
def __str__(self):
return Employee.company_name + " 계산대 직원: " + self.name
hyeon = Cashier("황현수", 8900, 4) # 객체 생성(오버라이딩 된)
print(hyeon) # __str__ 메소드 출력
## 변수 오버라이딩 -> 자식 클래스에서 다른 값을 대입
# 계산대 직원들만 시급 인상률 1.05로 바꾸기(1.03 -> 1.05)
# 자식 클래스에도 똑같은 이름의 변수를 두고 다른 값을 넣어주면 된다
class Cashier(Employee):
raise_percentage = 1.05
def __init__(self, name, wage, number_sold):
super().__init__(name, wage) # 자식 클래스에서 부모클래스의 메소드를 사용하고 싶을 때 사용하는 함수, self파라미터 쓸 필요 없다
self.number_sold = number_sold
def __str__(self):
return Employee.company_name + " 계산대 직원: " + self.name
hyeon = Cashier("황현수", 8900, 4) # 객체 생성(오버라이딩 된)
print(hyeon) # __str__ 메소드 출력
print(hyeon.raise_percentage) # 1.05
Python
복사
조민진 - 제한된 볼츠만 머신이 가시층과 은닉층으로 구성된 모델이라고 나와있는데 가시층과 입력층은 같은 건가요?
유성현
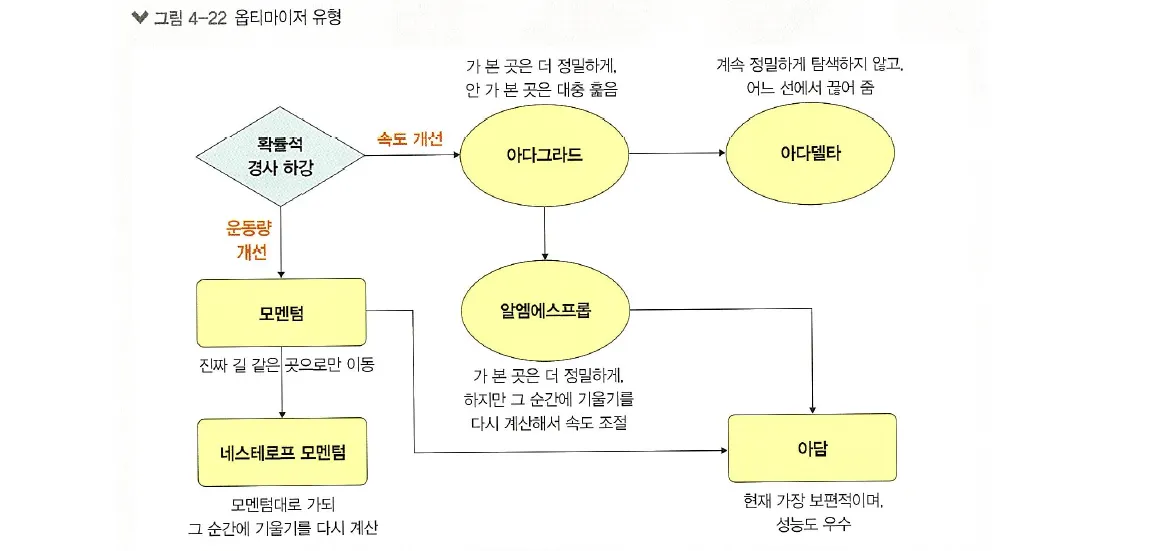
옵티마이저는 잘 모르면 일단 Adam을 쓰라고 할 정도로 보편적으로 사용하는 것 같습니다.
모델링할 때 각 데이터 종류나 딥러닝 분야의 다양한 상황에 맞게 최적화를 진행하는 것으로 알고 있는데
Adam의 성능이 떨어지는 경우는 없는지, 이외에 더 적합한 옵티마이저를 사용하는 경우는 어떤 것이 있을지 궁금합니다.
https://hiddenbeginner.github.io/deeplearning/paperreview/2019/12/29/paper_review_AdamW.html