

본인이 공부했던 해당 주차 스터디 내용을 정리해주세요.
.png&blockId=3259a88c-9a84-4cc1-889b-52dadd4777c8)
1주차 스터디 정리

딥러닝 개발 준비
딥러닝에 필요한 여러 라이브러리 및 모듈을 살펴보았습니다.
1. Tensorflow
import tensorflow as tf
INPUT_SIZE = (20, 1)
CONV_INPUT_SIZE = (1, 28, 28)
IS_TRAINING = True
inputs = tf.keras.layers.Input(shape = INPUT_SIZE)
dropout = tf.keras.layers.Dropout(rate = 0.2)(inputs)
conv = tf.keras.layers.Conv1D(
filters=10,
kernel_size=3,
padding='same',
activation=tf.nn.relu)(dropout)
max_pool = tf.keras.layers.MaxPool1D(pool_size = 3, padding = 'same')(conv)
flatten = tf.keras.layers.Flatten()(max_pool)
hidden = tf.keras.layers.Dense(units = 50, activation = tf.nn.relu)(flatten)
output = tf.keras.layers.Dense(units = 10, activation = tf.nn.softmax)(hidden)
Python
복사
간단한 CNN 구현
Tensorflow 2.x 에서는 keras 모듈이 텐서플로우에 포함되었습니다.
Functional API를 사용하여 하나의 CNN 구현 과정을 나타냈습니다.
2. Scikit-learn(Sklearn)
가장 대중적인 파이썬 머신러닝 라이브러리입니다.
이 책에서는 자연어처리를 위해 train - test set 분리(또는 validation set도 포함)를 위한 train_test_split 메서드와 여러 지도 및 비지도 머신러닝 모델들(regression, clustering 등) 및 간단한 vectorizer를 주로 사용합니다.
from sklearn.feature_extraction.text import CountVectorizer
text_data = ['나는 배가 고프다', '내일 점심 뭐먹지', '내일 공부 해야겠다', '점심 먹고 공부 해야지']
count_vectorizer = CountVectorizer()
count_vectorizer.fit(text_data)
print(count_vectorizer.vocabulary_)
sentence = [text_data[0]] # ['나는 배가 고프다']
print(count_vectorizer.transform(sentence).toarray())
Python
복사
count 기반 토크나이징
{'나는': 2, '배가': 6, '고프다': 0, '내일': 3, '점심': 7, '뭐먹지': 5, '공부': 1, '해야겠다': 8, '먹고': 4, '해야지': 9}
[[1 0 1 0 0 0 1 0 0 0]]
from sklearn.feature_extraction.text import TfidfVectorizer
text_data = ['나는 배가 고프다', '내일 점심 뭐먹지', '내일 공부 해야겠다', '점심 먹고 공부 해야지']
tfidf_vectorizer = TfidfVectorizer()
tfidf_vectorizer.fit(text_data)
print(tfidf_vectorizer.vocabulary_)
sentence = [text_data[3]] # ['점심 먹고 공부 해야지']
print(tfidf_vectorizer.transform(sentence).toarray())
Python
복사
TF - IDF 기반 토크나이징
{'나는': 2, '배가': 6, '고프다': 0, '내일': 3, '점심': 7, '뭐먹지': 5, '공부': 1, '해야겠다': 8, '먹고': 4, '해야지': 9}
[[0. 0.43779123 0. 0. 0.55528266 0.
0. 0.43779123 0. 0.55528266]]
3. Tokenizing Library
영어 토크나이징 라이브러리: NLTK, Spacy(상업용 목적으로 만들어짐)
from nltk.tokenize import word_tokenize
sentence = "Natural language processing (NLP) is a subfield of computer science, information engineering, and artificial intelligence concerned with the interactions between computers and human (natural) languages, in particular how to program computers to process and analyze large amounts of natural language data."
print(word_tokenize(sentence))
Python
복사
['Natural', 'language', 'processing', '(', 'NLP', ')', 'is', 'a', 'subfield', 'of', 'computer', 'science', ',', 'information', 'engineering', ',', 'and', 'artificial', 'intelligence', 'concerned', 'with', 'the', 'interactions', 'between', 'computers', 'and', 'human', '(', 'natural', ')', 'languages', ',', 'in', 'particular', 'how', 'to', 'program', 'computers', 'to', 'process', 'and', 'analyze', 'large', 'amounts', 'of', 'natural', 'language', 'data', '.']
한글 토크나이징 라이브러리: KoNLPy
from konlpy.tag import Okt
okt = Okt()
text = "한글 자연어 처리는 재밌다 이제부터 열심히 해야지ㅎㅎㅎ"
print(okt.morphs(text))
print(okt.morphs(text, stem=True)) # 형태소 단위로 나눈 후 어간을 추출
Python
복사
['한글', '자연어', '처리', '는', '재밌다', '이제', '부터', '열심히', '해야지', 'ㅎㅎㅎ']
['한글', '자연어', '처리', '는', '재밌다', '이제', '부터', '열심히', '하다', 'ㅎㅎㅎ']
4. Numpy
파이썬에서 사용하는 수치계산 라이브러리입니다. 대규모 다차원 배열을 쉽고 효율적으로 처리해주는 다양한 기능을 제공합니다. 특히 브로드캐스팅을 통해 넘파이 배열 연산을 간편하게 해줍니다.
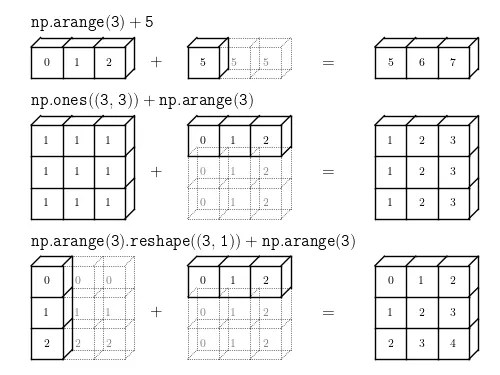
broadcasting 설명
출처: http://www.astroml.org/book_figures/appendix/fig_broadcast_visual.html
a = np.array([[1,2,3], [1,5,9], [3,5,7]])
print(a.ndim)
# 2
print(a.shape)
# (3,3)
print(a.size)
# 9
print(a.dtype)
# dtype('int32')
Python
복사
다양한 메서드 및 프로퍼티 제공
이외에도 겁나 많은 기능들을 제공하고 있으며, 판다스 및 사이킷런, 텐스플로우와 파이토치 등 여러 라이브러리에 호환되므로 데이터분석에 필수적인 라이브러리입니다.
5. Pandas
판다스 데이터 핸들링 및 분석을 위한 라이브러리입니다. 편리한 데이터 구조(Seris, DataFrame)와 데이터 분석 기능을 제공하기에 데이터 분석에 매우 유용합니다.
data_frame = pd.read_csv( './data_in/datafile.csv')
print(data_frame['A']) # A열의 데이터만 확인
# 2018-02-03 0.076547
# 2018-02-04 0.810574
# ...
# 2018-11-28 0.072067
# 2018-11-29 0.705263
# Freq: D, Name: A, Length: 300, dtype: float64
print(data_frame['A'][:3]) # A열의 데이터 중 앞의 10개만 확인
# 2018-02-03 0.076547
# 2018-02-04 0.810574
# 2018-02-05 0.071555
# Freq: D, Name: A, dtype: float64
data_frame['D'] = data_frame['A'] + data_frame['B'] # A열과 B열을 더한 새로운 C열 생성
print(data_frame ['D'])
# 2018-02-03 -0.334412
# 2018-02-04 1.799571
# 2018-02-05 0.843764
# 2018-02-06 1.079784
# 2018-02-07 0.734765
# Freq: D, Name: D, dtype: float64
data_frame.describe()
Python
복사
csv 파일 불러오기 및 데이터 핸들링
6. Matplotlib
matplotlib은 데이터 시각화를 위한 라이브러리입니다. 단 몇줄만으로 다양한 시각화 자료를 생성할 수 있습니다.
import matplotlib.pyplot as plt
import numpy as np
x = [1,3,5,7,9]
y = [100,200,300,400,500]
plt.plot(x, y)
x = np.linspace( - np.pi, np.pi, 128) # 연속적인 값을 갖는 배열
y = np.cos(x) # x 리스트에 대한 cos값 계산
plt.plot(x)
x = np.linspace(-np.pi, np.pi, 128) # 연속적인 값을 갖는 배열
y = np.cos(x) # x 리스트에 대한 cos값 계산
plt.plot(y)
Python
복사


7. Beautiful Soup
웹 크롤링(web crawling)에 주로 사용하는 라이브러리입니다. HTML 문서 또는 XML 문서에서 특정 태그에 감싸져 있는 데이터를 가져오는데 쓰입니다. 이 책에서는 HTML 문서의 태그를 제거하기 위해 사용합니다.
from bs4 import BeautifulSoup
string = '<body> 이 글은 Beautiful soup 라이브러리를 사용하는 방법에 대한 글입니다. <br> </br> 라이브러리를 사용하면 쉽게 HTML 태그를 제거할 수 있습니다.</body>'
string = BeautifulSoup(string,"html.parser").get_text() # HTML 태그를 제외한 텍스트만 가져온다
print(string) # 텍스트 확인
Python
복사
이 글은 Beautiful soup 라이브러리를 사용하는 방법에 대한 글입니다. 라이브러리를 사용하면 쉽게 HTML 태그를 제거할 수 있습니다.
8. Regular Expression
파이썬에서는 re 모듈을 활용하여 정규표현식을 적용합니다. 정규표현식이란 문자열에 나타나는 특정 문자 조합과 대응시키기 위해 사용되는 패턴입니다. 자연어처리 분야에서는 전처리 과정에서 주로 사용합니다.
import re
pattern = ' \W+'
re_pattern = re.compile(pattern)
pattern = ' \W+'
re_pattern = re.compile(pattern)
print(re.search( "(\w+)", "wow, it is awesome" ))
print(re.split("(\w+)", "wow, it is world of word"))
print(re.sub("\d", "number", "7 candy" ))
Python
복사
정규표현식 적용. search, split, sub 함수를 주로 사용.
<re.Match object; span=(0, 3), match='wow'>
['', 'wow', ', ', 'it', ' ', 'is', ' ', 'world', ' ', 'of', ' ', 'word', '']
number candy
위에서 활용한 라이브러리 등을 딥러닝을 이용하여 텍스트 분류, 텍스트 유사도 분석 등을 진행하고자 합니다.
.png&blockId=f5843d86-1abd-469f-a3db-507aace2e870)