

본인이 공부했던 해당 주차 세션을 본인 나름대로 정리해주세요!
LEVEL.1 → 세션 내용과 PPT를 살펴보면서 정리해주세요! 마지막에는 본인이 진행했던 실습문제와 과제 풀이를 넣어주시면 됩니다.
LEVEL.2 → 세션 내용과 PPT, 그리고 교재의 내용을 토대로 정리해주세요! 마지막에는 실습문제 및 과제 Colab 노트 링크(누구나 볼 수 있게 권한 설정 꼭 해주세요)를 첨부해주세요
.png&blockId=23c6a5e9-0664-42e2-b775-80ad95bd19f5)
1주차 세션 정리
5. 텍스트 유사도
텍스트 유사도(Text Similarity)란?
두 문장(또는 글)이 있을 때 두 문장 간의 유사도를 측정하는 것.
5-1. About Dataset
Quora Questions Pairs
쿼라(Quora)는 질문을 하고 다른 사용자들로부터 답변을 받을 수 있는 서비스로서 이 서비스에 올라온 여러 질문들 중에서 어떤 질문이 서로 유사한지 판단하는 모델을 만들고자 합니다. 유사도를 통해 비슷한 질문을 올릴려고 한다면, 답변을 받은 질문들을 제공하여 굳이 질문하지 않아도 답변을 얻을 수 있게 하는 것이 목적입니다.

쿼라 데이터셋
해당 데이터셋에는 아래 여섯가지 column이 있습니다.
•
id → row의 고유 인덱스입니다.
•
qid1 → 첫번째 질문에 대한 고유 인덱스입니다.
•
qid2 → 두번째 질문에 대한 고유 인덱스입니다.
•
question1 → 첫번째 질문입니다.
•
question2 → 두번째 질문입니다.
•
is_duplicate → question1과 question2가 유사하다면 1, 그렇지 않다면 0으로 값이 매겨져 있습니다.
Data Download
$ kaggle competitions download -c quora-question-pairs
Python
복사
터미널에서 실행해야함. 쿼라 데이터셋 페이지에서 대회 참여 억셉을 눌러야 정상 작동
5-2. EDA
해당 데이터셋에서 특이한 점은 테스트셋 파일인 test.csv의 용량이 train.csv보다 5배정도 큽니다. 이렇게 평가데이터의 크기가 큰 이유는 쿼라의 경우 질문에 대해 데이터의 수가 적다면 각각을 검색을 통해 중복을 찾아내는 편법을 사용할 수 있습니다. 따라서 이러한 편법을 방지하기 위해 쿼라에서 직접 컴퓨터가 만든 질문 쌍을 평가 데이터에 임의적으로 추가했습니다.
print("파일 크기: ")
for file in os.listdir(DATA_IN_PATH):
if 'csv' in file and 'zip' not in file:
print(file.ljust(30) + str(round(os.path.getsize(DATA_IN_PATH + file) / 1000000,2)) + 'MB')
Python
복사
파일 크기:
test.csv 314.02MB
train.csv 63.4MB
sample_submission.csv 22.35MB
Python
복사
test.csv가 train.csv보다 다섯배정도 큰 것을 볼 수 있습니다.
전제 학습 데이터의 개수를 알아보겠습니다.
print('전체 학습 데이터의 개수: {}'.format(len(train_data)))
Python
복사
전체 학습 데이터의 개수: 404290
Python
복사
전체 질문 쌍의 개수는 40만개 정도 됩니다.
전체 질문(두 개의 질문)을 한번에 분석하기 위해 판다스의 시리즈를 통해 두 개의 질문을 하나로 합칩니다
train_set = pd.Series(train_data['question1'].tolist()
+ train_data['question2'].tolist()).astype(str)
train_set.head()
Python
복사
0 What is the step by step guide to invest in sh...
1 What is the story of Kohinoor (Koh-i-Noor) Dia...
2 How can I increase the speed of my internet co...
3 Why am I mentally very lonely? How can I solve...
4 Which one dissolve in water quikly sugar, salt...
dtype: object
질문 중 중복된 질문들의 개수를 파악해봅니다.
print('train 데이터의 총 질문 수: {}'.format(len(np.unique(train_set))))
print('반복해서 나타나는 질문의 수: {}'.format(np.sum(train_set.value_counts() > 1)))
Python
복사
train 데이터의 총 질문 수: 537361
반복해서 나타나는 질문의 수: 111873
50만개의 데이터 중 중복 질문의 갯수는 11만개 가량이 됩니다.
즉, 80만 개의 데이터 중에서 53만개 정도가 unique한 데이터 이므로, 27만개 가량은 중복데이터 입니다. 그중 11만개의 데이터가 고유한 질문으로 이루어져 있습니다.(즉, 11만개의 질문 데이터가 두개 이상 중복되어 있으며, 그 수가 27만개 가량 됩니다)
데이터의 분포를 확인하기 위해 시각화를 진행해보겠습니다.
plt.figure(figsize=(12,5))
plt.hist(train_set.value_counts(), bins=50, alpha=0.5, color='r', label='word')
plt.yscale('log', nonposy='clip')
plt.title('Log-Histogram of question appearance counts')
plt.xlabel('Number of occurremces of question')
plt.ylabel('Number of questions')
Python
복사
중복 질문 시각화
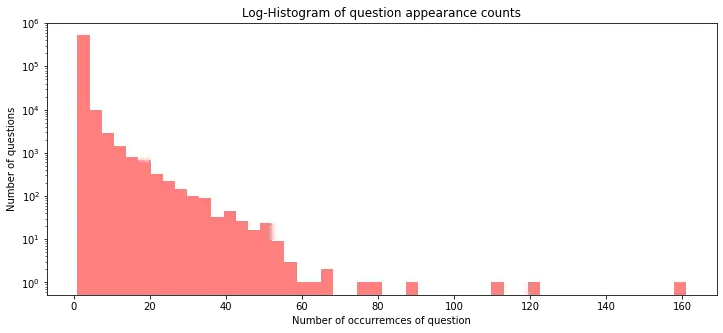
중복 횟수가 1인 질문들, 즉 유일한 질문이 가장 많고, 대부분의 질문이 중복 횟수가 50회 미만입니다. 그 이상으로는 이상치로 판단할 수 있으며, 160번 중복된 질문도 있음을 알 수 있습니다.
다음으로 질문의 중복 분포를 통계치로 수치화해봅니다.
print('중복 최대 개수: {}'.format(np.max(train_set.value_counts())))
print('중복 최소 개수: {}'.format(np.min(train_set.value_counts())))
print('중복 평균 개수: {:.2f}'.format(np.mean(train_set.value_counts())))
print('중복 표준편차: {:.2f}'.format(np.std(train_set.value_counts())))
print('중복 중간길이: {}'.format(np.median(train_set.value_counts())))
# 사분위의 대한 경우는 0~100 스케일로 되어있음
print('제 1 사분위 중복: {}'.format(np.percentile(train_set.value_counts(), 25)))
print('제 3 사분위 중복: {}'.format(np.percentile(train_set.value_counts(), 75)))
Python
복사
중복 최대 개수: 161
중복 최소 개수: 1
중복 평균 개수: 1.50
중복 표준편차: 1.91
중복 중간길이: 1.0
제 1 사분위 중복: 1.0
제 3 사분위 중복: 1.0
평균적으로 1.5개의 중복을 가지고 있음을 알 수 있으며, 표준편차는 1.9입니다
중복이 발생하는 횟수의 평균이 1.5라는 것은 많은 데이터가 최소 1개 이상 중복돼 있음을 의미합니다.
boxplot을 통해 데이터를 직관적으로 살펴보겠습니다.
plt.figure(figsize=(12, 5))
plt.boxplot([train_set.value_counts()],
labels=['counts'],
showmeans=True)
Python
복사
중복 질문 갯수 boxplot

중복 횟수의 이상치(outliers)가 너무 넓고 많이 분포되어 있음을 알 수 있습니다.
데이터의 어떤 단어들이 분포되어 있는지 확인해보겠습니다.
from wordcloud import WordCloud
cloud = WordCloud(width=800, height=600).generate(" ".join(train_set.astype(str)))
plt.figure(figsize=(15, 10))
plt.imshow(cloud)
plt.axis('off')
Python
복사
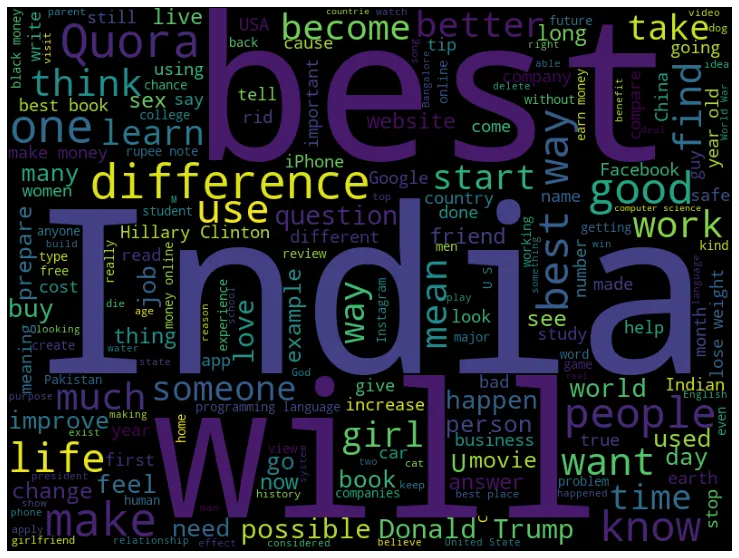
워드클라우드를 살펴보면 best, india, donal Trump, Quora 등의 단어가 많이 사용됨을 알 수 있습니다.
이제 질문 텍스트가 아닌 데이터의 라벨(y)인 "is_duplicate"에 대해 확인해보겠습니다.
fig, axe = plt.subplots(ncols=1)
fig.set_size_inches(6, 3)
sns.countplot(train_data['is_duplicate'])
Python
복사
데이터 라벨에 대한 분포

40만개의 데이터 중에서 중복이 아닌 데이터가 25만 개이고, 중복된 데이터가 15만 개 임을 알 수 있습니다.
편향된 라벨 데이터는 학습이 원활하게 되지 않을 수 있으므로, 최대한 라벨의 개수를 균형 있게 맞춰준 후 진행하는 것이 좋습니다.
다음으로 텍스트 데이터의 길이를 분석해보도록 하겠습니다.
train_length = train_set.apply(len) # 문자 단위로 분석하기 위한 데이터 길이를 담은 변수 생성
plt.figure(figsize=(12,5))
plt.hist(train_length, bins=200, range = [0, 200], facecolor='r', density=True, label='train')
plt.title('Normalised histogram of character count in questions', fontsize=15)
plt.legend()
plt.xlabel('Number of characters', fontsize=15)
plt.ylabel('Probaability', fontsize=15)
Python
복사
질문당 단어 개수 분포

데이터의 각 질문의 길이 분포는 15~150에 대부분 모여 있으며 길이가 150에서 급격하게 줄어드는 것을 볼 수 있는데, 이는 Quora의 질문 길이 제한이 150개 정도라는 것을 추정해 볼 수 있습니다.
길이값을 사용해 여러 가지 통곗값을 확인해 보겠습니다.
print('질문 길이 최대 값: {}'.format(np.max(train_length)))
print('질문 길이 평균 값: {:.2f}'.format(np.mean(train_length)))
print('질문 길이 표준편차: {:.2f}'.format(np.std(train_length)))
print('질문 길이 중간 값: {}'.format(np.median(train_length)))
print('질문 길이 제 1 사분위: {}'.format(np.percentile(train_length, 25)))
print('질문 길이 제 3 사분위: {}'.format(np.percentile(train_length, 75)))
Python
복사
질문 길이 최대 값: 1169
질문 길이 평균 값: 59.82
질문 길이 표준편차: 31.96
질문 길이 중간 값: 51.0
질문 길이 제 1 사분위: 39.0
질문 길이 제 3 사분위: 72.0
평균 길이가 대략 60 정도라는 것을 확인할 수 있습니다. 하지만 최댓값을 확인해 보면 1169로서 평균, 중간값에 비해 매우 큰 차이를 보입니다. 이런 데이터는 제외하고 학습하는 것이 좋습니다.
데이터의 질문 길이값에 대해서도 boxplot을 확인해보겠습니다
plt.figure(figsize=(12, 5))
plt.boxplot(train_length,
labels=['char counts'],
showmeans=True)
Python
복사
데이터 길이를 나타내는 박스 플롯(문자단위)
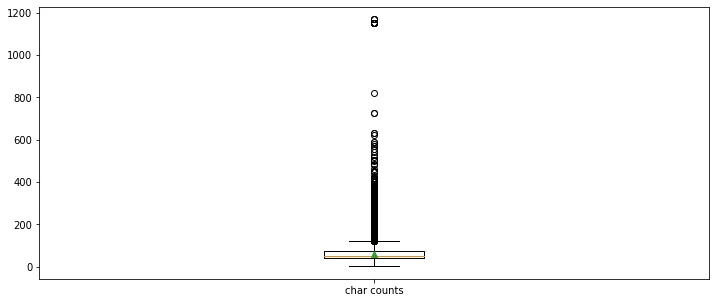
이제 문자 단위가 아닌 단어 단위로 데이터값을 분석해 보겠습니다.
train_word_counts = train_set.apply(lambda x: len(x.split(' ')))
plt.figure(figsize=(12,5))
plt.hist(train_word_counts, bins=50, range = [0, 50], facecolor='r', density=True, label='train')
plt.title('Normalised histogram of word count in questions', fontsize=15)
plt.legend()
plt.xlabel('Number of words', fontsize=15)
plt.ylabel('Probaability', fontsize=15)
Python
복사
데이터 길이에 따른 질의 확률 분포(단어 단위)
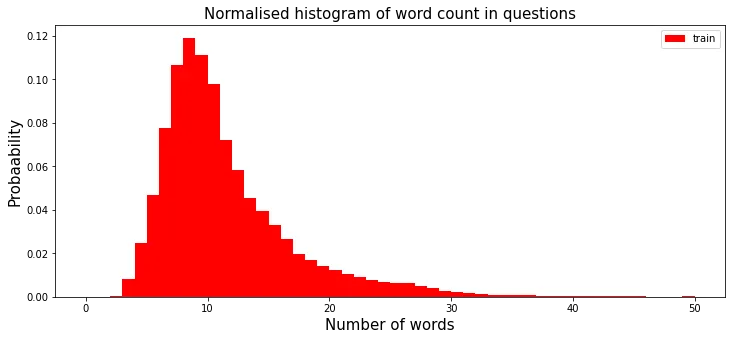
히스토그램을 보면 대부분 10개 정도의 단어로 구성된 데이터가 가장 많다는 것을 볼 수 있습니다. 더불어 20개 이상의 단어로 구성된 데이터는 매우 적다는 것을 확인할 수 있습니다
데이터의 단어 개수에 대해서도 각 통곗값을 확인해 보겠습니다.
print('질문 단어 개수 최대 값: {}'.format(np.max(train_word_counts)))
print('질문 단어 개수 평균 값: {:.2f}'.format(np.mean(train_word_counts)))
print('질문 단어 개수 표준편차: {:.2f}'.format(np.std(train_word_counts)))
print('질문 단어 개수 중간 값: {}'.format(np.median(train_word_counts)))
print('질문 단어 개수 제 1 사분위: {}'.format(np.percentile(train_word_counts, 25)))
print('질문 단어 개수 제 3 사분위: {}'.format(np.percentile(train_word_counts, 75)))
print('질문 단어 개수 99 퍼센트: {}'.format(np.percentile(train_word_counts, 99)))
Python
복사
질문 단어 개수 최대 값: 237
질문 단어 개수 평균 값: 11.06
질문 단어 개수 표준편차: 5.89
질문 단어 개수 중간 값: 10.0
질문 단어 개수 제 1 사분위: 7.0
질문 단어 개수 제 3 사분위: 13.0
질문 단어 개수 99 퍼센트: 31.0
평균 개수의 경우 11개가 단어 개수의 평균임을 알 수 있고, 최대값은 237개임을 알 수 있습니다.
단어 개수의 대한 boxplot를 그려보겠습니다.
plt.figure(figsize=(12, 5))
plt.boxplot(train_word_counts,
labels=['counts'],
showmeans=True)
Python
복사
데이터 길이를 나타내는 박스 플롯(단어 단위)
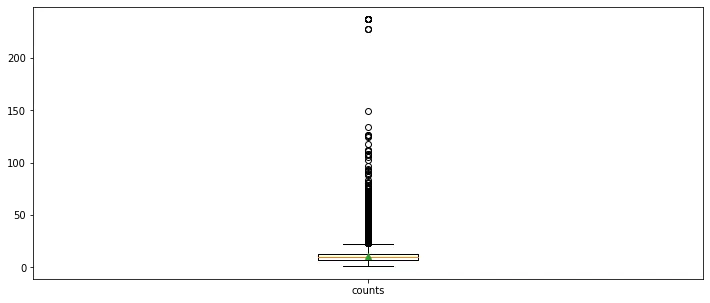
이상치가 넓고 많이 분포돼 있음을 알 수 있습니다.
output = train_set.apply(len)
[0] "What is the step by step guide to invest in sh..."
[1] "What is the step by step guide to invest in sh..."
[2] "What is the step by step guide to invest in sh..."
...
[400000]
....
output
[0] 80
[1] 80
[2] 80
....
[400000] 50
특수 문자 중 구두점, 물음표, 마침표가 사용된 비율과 수학 기호가 사용된 비율, 대/소문자의 비율을 확인해봅니다.
qmarks = np.mean(train_set.apply(lambda x: '?' in x)) # 물음표가 구두점으로 쓰임
math = np.mean(train_set.apply(lambda x: '[math]' in x)) # []
fullstop = np.mean(train_set.apply(lambda x: '.' in x)) # 마침표
capital_first = np.mean(train_set.apply(lambda x: x[0].isupper())) # 첫번째 대문자
capitals = np.mean(train_set.apply(lambda x: max([y.isupper() for y in x]))) # 대문자가 몇개
numbers = np.mean(train_set.apply(lambda x: max([y.isdigit() for y in x]))) # 숫자가 몇개
print('물음표가있는 질문: {:.2f}%'.format(qmarks * 100))
print('수학 태그가있는 질문: {:.2f}%'.format(math * 100))
print('마침표를 포함한 질문: {:.2f}%'.format(fullstop * 100))
print('첫 글자가 대문자 인 질문: {:.2f}%'.format(capital_first * 100))
print('대문자가있는 질문: {:.2f}%'.format(capitals * 100))
print('숫자가있는 질문: {:.2f}%'.format(numbers * 100))
Python
복사
물음표가있는 질문: 99.87%
수학 태그가있는 질문: 0.12%
마침표를 포함한 질문: 6.31%
첫 글자가 대문자 인 질문: 99.81%
대문자가있는 질문: 99.95%
숫자가있는 질문: 11.83%
대문자의 경우 모든 질문이 보편적으로 가지고 있는 특징이므로, 여기서는 보편적인 특징에 대해서는 제거한다.
5-2. Preprocessing
전처리를 하기 위한 라이브러리를 불러옵니다.
import pandas as pd
import numpy as np
import re
import json
from tensorflow.python.keras.preprocessing.text import Tokenizer
from tensorflow.python.keras.preprocessing.sequence import pad_sequences
Python
복사
5-3-1. Train Set preprocessing
먼저 수행할 전처리 작업은, 앞서 확인했던 라벨 개수의 균형을 맞추는 것입니다. 따라서 중복이 아닌 개수가 비슷하도록 데이터의 일부를 다시 뽑도록 합니다.
train_data = pd.read_csv(DATA_IN_PATH + 'train.csv', encoding='utf-8') #데이터 불러오기
train_pos_data = train_data.loc[train_data['is_duplicate'] == 1]
train_neg_data = train_data.loc[train_data['is_duplicate'] == 0]
class_difference = len(train_neg_data) - len(train_pos_data)
sample_frac = 1 - (class_difference / len(train_neg_data))
train_neg_data = train_neg_data.sample(frac = sample_frac)
print("중복 질문 개수: {}".format(len(train_pos_data)))
print("중복이 아닌 질문 개수: {}".format(len(train_neg_data)))
Python
복사
중복 질문 개수: 149263
중복이 아닌 질문 개수: 149263
두 변수의 길이의 차이를 계산하고 샘플링하기 위해 적은 데이터(중복 질문)의 개수가 많은 데이터(중복이 아닌 질문)에 대한 비율을 계산합니다. 그리고 개수가 많은 데이터에 대해 방금 구한 비율만큼 샘플링하면 두 데이터 간의 개수가 거의 비슷해집니다.
전처리를 진행하기 위해 두 데이터를 합친 후 진행합니다.
train_data = pd.concat([train_neg_data, train_pos_data])
Python
복사
우선 학습 데이터의 질 문 쌍을 하나의 질문 리스트로 만들고, 정규 표현식을 사용해 물음표와 마침표 같은 구두점 및 기호를 제거하고 모든 문자를 소문자로 바꾸는 처리를 합니다.
FILTERS = "([~.,!?\"':;)(])"
change_filter = re.compile(FILTERS)
question1 = [str(s) for s in train_data['question1']]
question2 = [str(s) for s in train_data['question2']]
filtered_question1 = list()
filtered_question2 = list()
for q in question1:
filtered_question1.append(re.sub(change_filter, "", q).lower())
for q in question2:
filtered_question2.append(re.sub(change_filter, "", q).lower())
Python
복사
다음으로 문자열 토크나이징을 진행합니다.
tokenizer = Tokenizer()
tokenizer.fit_on_texts(filtered_question1 + filtered_question2)
question1_sequence = tokenizer.texts_to_sequences(filtered_question1)
question2_sequence = tokenizer.texts_to_sequences(filtered_question2)
Python
복사
토크나이징 객체를 만들 때는 두 질문 텍스트를 합친 리스트에 대해 적용하고, 토크나이징은 해당 객체를 확용해 각 질문에 대해 따로 진행합니다. 이렇게 사용하는 이유는 두 질문에 대해 토크나이징 방식을 동일하게 진행하고, 두 질문을 합쳐 전체 단어 사전을 만들기 위해서입니다.
이제 모델에 적용하기 위해 특정 길이로 동일하게 맞추는 작업을 진행합니다.
MAX_SEQUENCE_LENGTH = 31
q1_data = pad_sequences(question1_sequence, maxlen=MAX_SEQUENCE_LENGTH, padding='post')
q2_data = pad_sequences(question2_sequence, maxlen=MAX_SEQUENCE_LENGTH, padding='post')
Python
복사
MAX_SEQ_LEN: 5
"I LOVE NLP" → pad_sequences → ["I", "LOVE", "NLP", "<pad>", "<pad>"]
최대 길이의 경우 앞서 데이터분석에서 확인했던 단어 개수의 99퍼센트인 31로 설정했습니다.
전처리 모듈의 패딩함수를 사용해 최대 길이로 자르고 짧은 데이터에 대해서는 데이터 뒤에 패딩값을 채워넣었습니다.
전처리가 끝난 후 데이터를 저장합니다. 더불어 저장하기 전에 라벨값과 단어 사전을 저장하기 위해 값을 저장한 후 각 데이터의 크기를 확인해봅니다.
word_vocab = {}
word_vocab = tokenizer.word_index
word_vocab["<PAD>"] = 0
labels = np.array(train_data['is_duplicate'], dtype=int)
print('Shape of question1 data: {}'.format(q1_data.shape))
print('Shape of question2 data: {}'.format(q2_data.shape))
print('Shape of label: {}'.format(labels.shape))
print('Words in index: {}'.format(len(word_vocab)))
Python
복사
Shape of question1 data: (298526, 31)
Shape of question2 data: (298526, 31)
Shape of label: (298526,)
Words in index: 76264
단어사전의 전체 길이인 전체 단어 개수는 76,264개로 되어 있음을 알 수 있습니다.
각 질문과 라벨 데이터를 로컬에 저장합니다.
data_configs = {}
data_configs['vocab'] = word_vocab
data_configs['vocab_size'] = len(word_vocab)
TRAIN_Q1_DATA = 'q1_train.npy'
TRAIN_Q2_DATA = 'q2_train.npy'
TRAIN_LABEL_DATA = 'label_train.npy'
DATA_CONFIGS = 'data_configs.npy'
np.save(open(DATA_IN_PATH + TRAIN_Q1_DATA, 'wb'), q1_data)
np.save(open(DATA_IN_PATH + TRAIN_Q2_DATA, 'wb'), q2_data)
np.save(open(DATA_IN_PATH + TRAIN_LABEL_DATA, 'wb'), labels)
json.dump(data_configs, open(DATA_IN_PATH + DATA_CONFIGS,'w'))
Python
복사
5-3-2. Test Set preprocessing
Test셋도 마찬가지로 전처리를 진행하도록 하겠습니다.
test_data = pd.read_csv(DATA_IN_PATH + 'test.csv', encoding='utf-8')
valid_ids = [type(x) ==int for x in test_data.test_id]
test_data = test_data[valid_ids].drop_duplicates()
test_questions1 = [str(s) for s in test_data['question1']]
test_questions2 = [str(s) for s in test_data['question2']]
filtered_test_questions1 = list()
filtered_test_questions2 = list()
for q in test_questions1:
filtered_test_questions1.append(re.sub(change_filter, "", q).lower())
for q in test_questions2:
filtered_test_questions2.append(re.sub(change_filter, "", q).lower())
test_questions1_sequence = tokenizer.texts_to_sequences(filtered_test_questions1)
test_questions2_sequence = tokenizer.texts_to_sequences(filtered_test_questions2)
test_q1_data = pad_sequences(test_questions1_sequence, maxlen=MAX_SEQUENCE_LENGTH, padding='post')
test_q2_data = pad_sequences(test_questions2_sequence, maxlen=MAX_SEQUENCE_LENGTH, padding='post')
test_id = np.array(test_data['test_id'])
print('Shape of question1 data: {}'.format(test_q1_data.shape))
print('Shape of question2 data:{}'.format(test_q2_data.shape))
print('Shape of ids: {}'.format(test_id.shape))
Python
복사
Shape of question1 data: (2345796, 31)
Shape of question2 data:(2345796, 31)
Shape of ids: (2345796,)
여기서 사용하는 토크나이징 객체는 이전에 학습 데이터에서 사용했던 객체를 사용해야 동일한 인덱스를 가집니다.
평가데이터의 경우 라벨이 존제하지 않으므로 라벨은 저장할 필요가 없습니다. 또한 평가 데이터에 대한 단어 사전 정보도 이미 학습 데이터 전처리 과정에서 저장했기 때문에 추가로 저장할 필요가 없습니다. 하지만 캐글에 제출할 때를 생각해보면 평가 데이터의 id 값이 필요하므로 평가 데이터의 id값을 넘파이 배열로 만들어 추가합니다.
전처리를 진행한 평가데이터는 이후 모델이 완성되면 사용하기 위해 로컬에 저장합니다
TEST_Q1_DATA = 'test_q1.npy'
TEST_Q2_DATA = 'test_q2.npy'
TEST_ID_DATA = 'test_id.npy'
np.save(open(DATA_IN_PATH + TEST_Q1_DATA, 'wb'), test_q1_data)
np.save(open(DATA_IN_PATH + TEST_Q2_DATA , 'wb'), test_q2_data)
np.save(open(DATA_IN_PATH + TEST_ID_DATA , 'wb'), test_id)
Python
복사
5-4. Modeling & Evaluation
5-4-1. XGBoost
모델 설명
XGBoost란, 'eXtream Gradient Boosing'의 약자로, 앙상블의 한 방법인 부스팅 기법을 사용하는 방법입니다.
부스팅 기법이란?

부스팅을 설명하기 전에, 앙상블 기법을 설명드리겠습니다.
앙상블 기법이란, 여러 개의 학습 알고리즘을 사용해 더 좋은 성능을 얻는 방법을 뜻합니다.
앙상블 기법에는 배깅(Bagging)과 부스팅(Boosting)이라는 방법이 있습니다.
배깅이란?
여러 개의 학습 알고리즘, 모델을 통해 각각 결과를 예측하고 모든 결과를 동등하게 보고 취합해서 결과를 얻는 방식입니다. 예를 들면 랜덤 포레스트(random forest) 모델의 경우 여러 개의 의사결정 트리 결괏값의 평균을 통해 결과를 얻는 배깅이라는 방법을 사용한 것입니다.
부스팅이란?
부스팅은 각 결과를 순차적으로 취합하는데, 단순히 하나씩 취합하는 방법이 아니라 이전 알고리즘, 모델이 학습 후 잘못 예측한 부분에 가중치를 줘서 다시 모델로 가서 학습하는 방식입니다.
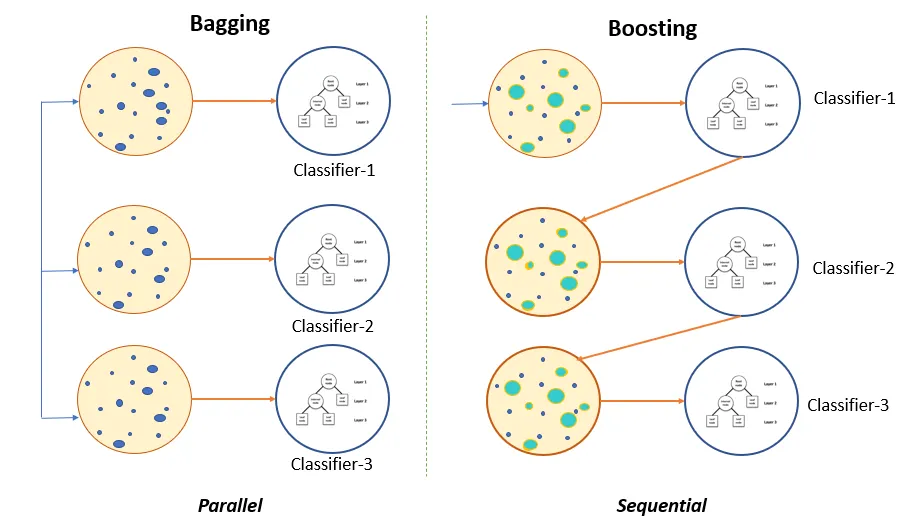
앙상블 기법중 하나인 Bagging과 Boosting의 차이점
XGBoost는 부스팅 기법 중 트리 부스팅(Tree Boosting) 기법을 활용한 모델입니다. 즉, 트리 부스팅 기법이란 여러 개의 의사결정 트리를 사용하지만, 단순히 결과를 평균내는 것이 아니라 결과를 보고 오답에 대해 가중치를 부여합니다. 그리고 가중치가 적용된 오답에 대해서는 관심을 가지고 정답이 될 수 있도록 결과를 만들고 해당 결과에 대한 다른 오답을 찾아 다시 똑같은 작업을 반복적으로 진행하는 것입니다.
모델 구현
TRAIN_Q1_DATA_FILE = 'q1_train.npy'
TRAIN_Q2_DATA_FILE = 'q2_train.npy'
TRAIN_LABEL_DATA_FILE = 'label_train.npy'
# 훈련 데이터를 가져옵니다.
train_q1_data = np.load(open(DATA_IN_PATH + TRAIN_Q1_DATA_FILE, 'rb'))
train_q2_data = np.load(open(DATA_IN_PATH + TRAIN_Q2_DATA_FILE, 'rb'))
train_labels = np.load(open(DATA_IN_PATH + TRAIN_LABEL_DATA_FILE, 'rb'))
Python
복사
전처리한 훈련 데이터를 불러옵니다.
현재 두 질문이 따로 구성돼 있으므로 하나의 질문 쌍으로 만듭니다.
train_input = np.stack((train_q1_data, train_q2_data), axis=1)
print(train_input.shape)
Python
복사
(298526, 2, 31)
전체 29만 개 정도의 데이터에 대해 두 질문이 각각 31개의 질문 길이를 가지고 있음을 확인 할 수 있습니다.
학습 데이터의 일부를 모델 검증을 위한 검증 데이터로 만들어 둡니다.
from sklearn.model_selection import train_test_split
train_input, eval_input, train_label, eval_label = train_test_split(train_input,
train_labels,
test_size=0.2,
random_state=42)
Python
복사
전체 데이터의 20%를 검증 데이터로 만들어 두었습니다.
이제 XG부스트를 설치하고 불러온 뒤 모델에 적용하기 위해 입력값을 형식에 맞게 만들어 보겠습니다.
import xgboost as xgb
train_data = xgb.DMatrix(train_input.sum(axis=1), label=train_label)
eval_data = xgb.DMatrix(eval_input.sum(axis=1), label=eval_label)
data_list = [(train_data, 'train'), (eval_data, 'valid')]
Python
복사
XG 부스트 모델을 사용하려면 입력값을 xgb 라이브러리의 데이터 형식인 DMatrix 형태로 만들어야 합니다.
이제 모델을 학습하기 위해 몇가지 선택해야 하는 옵션을 딕셔너리에 만들어 놓고, 본격적으로 학습을 진행해보겠습니다.
params = {}
params['objective'] = 'binary:logistic'
params['eval_metric'] = 'rmse'
bst = xgb.train(params, train_data,
num_boost_round=1000,
evals = data_list,
early_stopping_rounds=10)
Python
복사
결과
[0] train-rmse:0.48383 valid-rmse:0.48422
[1] train-rmse:0.47336 valid-rmse:0.47409
[2] train-rmse:0.46684 valid-rmse:0.46787
[3] train-rmse:0.46190 valid-rmse:0.46321
[4] train-rmse:0.45827 valid-rmse:0.45988
[5] train-rmse:0.45561 valid-rmse:0.45746
...
[530] train-rmse:0.36253 valid-rmse:0.41747
[531] train-rmse:0.36235 valid-rmse:0.41747
[532] train-rmse:0.36233 valid-rmse:0.41747
[533] train-rmse:0.36225 valid-rmse:0.41745
[534] train-rmse:0.36213 valid-rmse:0.41746
[535] train-rmse:0.36198 valid-rmse:0.41744
[536] train-rmse:0.36186 valid-rmse:0.41742
Plain Text
복사
목적함수의 경우 이진 로지스틱 함수를 사용하며, 평가 지표의 경우 RMSE를 사용합니다.
해당 모델을 평가데이터에 적용하여 예측값을 만듭니다.
# test set 불러오기
TEST_Q1_DATA_FILE = 'test_q1.npy'
TEST_Q2_DATA_FILE = 'test_q2.npy'
TEST_ID_DATA_FILE = 'test_id.npy'
test_q1_data = np.load(open(DATA_IN_PATH + TEST_Q1_DATA_FILE, 'rb'))
test_q2_data = np.load(open(DATA_IN_PATH + TEST_Q2_DATA_FILE, 'rb'))
test_id_data = np.load(open(DATA_IN_PATH + TEST_ID_DATA_FILE, 'rb'))
# test set predict
test_input = np.stack((test_q1_data, test_q2_data), axis=1)
test_data = xgb.DMatrix(test_input.sum(axis=1))
test_predict = bst.predict(test_data)
# 예측값 저장
DATA_OUT_PATH = './data_out/quora/'
if not os.path.exists(DATA_OUT_PATH):
os.makedirs(DATA_OUT_PATH)
output = pd.DataFrame({'test_id': test_id_data, 'is_duplicate': test_predict})
output.to_csv(DATA_OUT_PATH + 'simple_xgb.csv', index=False)
Python
복사
Score
해당 데이터를 캐글에 제출할 경우 Score가 대략 0.56739가 나왔습니다.
5-4-2. CNN(Convolution Neural Network)
모델 설명
CNN 텍스트 유사도 분석 모델은 문장에 대한 의미 벡터를 합성곱 신경망을 통해 추출해서 그 벡터에 대한 유사도를 측정합니다.
NLP 분야 CNN 모델을 사용하는 방법

다음 두 문장이 있다고 합시다.
I love deep NLP
첫번째 문장은 "I love deep NLP"인데, 해당 문장은 기준 문장이라고 정의합니다.
두번째 문장은 "Deep NLP is awesome"인데, 해당 문장은 대상 문장이라고 정의합니다.
이 두 문장은 의미가 상당히 유사합니다. 만약 학습이 진행된 후에 두 문장에 대한 유사도를 측정하고자 한다면, 아마도 높은 문장 유사도 점수를 보일 것입니다. 이처럼 문장이 의미적으로 가까우면 유사도 점수는 높게 표현될 것이고, 그렇지 않을 경우에는 낮게 표현될 것입니다.
모델에 데이터를 입력하기 전에 기준 문장과 대상 문장에 대해서 인덱싱을 거쳐 문자열 형태로 문장을 인덱스 벡터 형태로 구성합니다. 그리고 인덱스 벡터로 구성된 문장 정보는 임베딩 과정을 통해 각 단어가 임베딩 벡터로 바뀐 행렬로 구성될 것입니다. 이렇게 임베딩 과정을 통해 나온 문장 행렬은 기준 문장과 대상 문장 각각에 해당하는 CNN 블록을 거치게 합니다. CNN블록은 합성곱 층과 맥스 풀링(Max Pooling) 층을 합친 하나의 신경망을 말합니다. 두 블록을 거쳐 나온 벡터는 문장에 대한 의미 벡터가 됩니다. 두 문장에 대한 의미 벡터를 가지고 여러 방식으로 유사도를 구할 수 있는데, 여기서는 완전연결층을 거친 후 최종적으로 로지스틱 회귀 방법을 통해 문장 유사도 점수를 측정할 예정입니다.
정리하면 다음과 같습니다.
•
기준 문장과 대상 문장에 대해 인덱스 벡터 형태로 구성
•
인덱스 벡터를 임베딩 과정을 통해 임베딩 벡터로 변환
•
이를 쌓아 문장 행렬을 만든다.
•
해당 행렬을 CNN 블록을 거친다.
•
블록을 통해 나온 의미 벡터를 완전연결 층을 거치게 한다.
•
로지스틱 회귀 방법으로 유사한지(label: 1) 유사하지 않은지(label: 0) 측정한다.
모델을 구현하기 전 데이터를 불러옵니다.
from tensorflow.keras import layers
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
DATA_IN_PATH = './data_in/quora/'
DATA_OUT_PATH = './data_out/quora/'
TRAIN_Q1_DATA_FILE = 'q1_train.npy'
TRAIN_Q2_DATA_FILE = 'q2_train.npy'
TRAIN_LABEL_DATA_FILE = 'label_train.npy'
DATA_CONFIGS = 'data_configs.npy'
q1_data = np.load(open(DATA_IN_PATH + TRAIN_Q1_DATA_FILE, 'rb'))
q2_data = np.load(open(DATA_IN_PATH + TRAIN_Q2_DATA_FILE, 'rb'))
labels = np.load(open(DATA_IN_PATH + TRAIN_LABEL_DATA_FILE, 'rb'))
prepro_configs = json.load(open(DATA_IN_PATH + DATA_CONFIGS, 'r'))
Python
복사
모델 구현
모델을 구현하기 전에 먼저 SentenceEmbedding 모듈을 정의합니다. 이 모듈을 통해 문장에 대한 정보를 하나의 벡터로 만듭니다. 이 과정에서 합성곱 레이어와 맥스 풀링 레이어가 활용됩니다.

import tensorflow as tf
class SentenceEmbedding(layers.Layer):
def __init__(self, args):
super(SentenceEmbedding, self).__init__()
self.conv = layers.Conv1D(args.conv_num_filters, args.conv_window_size,
activation = tf.keras.activations.relu,
padding='same')
self.max_pool = layers.MaxPool1D(args.max_pool_seq_len, 1)
self.dense = layers.Dense(args.sent_embedding_dimension, activation=tf.keras.activations.relu)
def call(self, x):
x = self.conv(x)
x = self.max_pool(x)
x = self.dense(x)
return tf.squeeze(x, 1)
Python
복사
먼저 합성곱 레이어의 경우 합성곱을 적용할 필터의 개수와 필터의 크기, 활성화 함수, 패딩 방법까지 인자로 받습니다.
•
활성화 함수로는 relu 함수를 사용합니다.
•
패딩 방법으로는 입력값과 출력에 대한 크기를 동일하게 하기 위해 'same' 이라는 값으로 설정합니다.
•
맥스 풀링 레이어의 경우 전체 시퀸스에서 가장 특징이 되는 높은 피쳐값만 선택해 문장 벡터를 구성하게 합니다. 풀링 영역의 대한 크기는 max_pool_seq_len을 통해 정의하고, pool_size에 1을 입력합니다.
•
Dense 레이어에는 문장 임베딩 벡터로 출력할 차원 수를 정의합니다.
이렇게 정의한 모듈들을 call 함수에서 호출해 모듈 연산 과정을 정의합니다.
이제 모델을 만들어 보겠습니다.
class SentenceSimilarityModel(tf.keras.Model):
def __init__(self, args):
super(SentenceSimilarityModel, self).__init__(name = args.model_name)
self.word_embedding = layers.Embedding(args.vocab_size, args.word_embedding_dimension)
self.base_encoder = SentenceEmbedding(args)
self.hypo_encoder = SentenceEmbedding(args)
self.dense = layers.Dense(args.hidden_dimension, activation = tf.keras.activations.relu)
self.logit = layers.Dense(1, activation = tf.keras.activations.sigmoid)
self.dropout = layers.Dropout(args.dropout_rate)
def call(self, x):
x1, x2 = x
b_x = self.word_embedding(x1)
h_x = self.word_embedding(x2)
b_x = self.dropout(b_x)
h_x = self.dropout(h_x)
b_x = self.base_encoder(b_x)
h_x = self.hypo_encoder(h_x)
e_x = tf.concat([b_x, h_x], -1)
e_x = self.dense(e_x)
e_x = self.dropout(e_x)
return self.logit(e_x)
Python
복사
모델 구현 시 사용되는 레이어는 크게 3가지 모듈을 사용합니다.
1.
단어 임베딩 레이어
2.
문장 임베딩 레이어
3.
차원 변환을 위한 Dense 레이어
Dense 레이어는 두 base와 hypothesis 문장에 대한 유사도를 계산하기 위해 만들어진 레이어입니다.
모델에 사용할 하이퍼파라미터를 정의해보겠습니다.
from argparse import Namespace
model_name = 'cnn_similarity'
BATCH_SIZE = 1024
NUM_EPOCHS = 100
VALID_SPLIT = 0.1
MAX_LEN = 31
args = Namespace(
model_name= model_name,
vocab_size = prepro_configs['vocab_size'],
word_embedding_dimension = 100,
conv_num_filters = 300,
conv_window_size = 3,
max_pool_seq_len = MAX_LEN,
sent_embedding_dimension = 128,
dropout_rate = 0.2,
hidden_dimension = 200,
output_dimension =1
)
Python
복사
•
vocab_size와 word_embedding_dimension은 단어 임베딩을 위한 차원 값입니다.
•
conv_num_filters와 conv_window_size는 합성곱 레이어를 위한 차원값과 윈도우 크기입니다.
•
max_pool_seq_len은 맥스 풀링을 위한 고정 길이입니다.
•
sent_embedding_dimension은 문장 임베딩에 대한 차원값입니다.
•
hidden_demension은 마지막 Dense 레이어에 대한 차원값입니다.
모델 생성
하이퍼파라미터가 구성돼었으니 모델을 생성해봅니다.
model = SentenceSimilarityModel(args)
model.compile(optimizer=tf.keras.optimizers.Adam(1e-3),
loss=tf.keras.losses.BinaryCrossentropy(),
metrics=[tf.keras.metrics.BinaryAccuracy(name='accuracy')])
Python
복사
여기서 손실 함수는 이진 교차 엔트로피(binary cross entropy) 함수를 사용하며, 옵티마이저의 경우 Adam을 사용합니다. 평가의 경우 중복을 예측한 것에 대한 정확도를 측정합니다.
모델 학습
모델을 생성했으니 모델을 학습시킵니다.
# 오버피팅을 막기 위한 ealrystop
earlystop_callback = EarlyStopping(monitor='val_accuracy',
min_delta=0.0001,
patience=1)
checkpoint_path = DATA_OUT_PATH + model_name +'/weights.h5'
checkpoint_dir = os.path.dirname(checkpoint_path)
if os.path.exists(checkpoint_dir):
print("{} -- Folder already exists \n".format(checkpoint_dir))
else:
os.makedirs(checkpoint_dir, exist_ok=True)
print("{} -- Folder create complete \n".format(checkpoint_dir))
cp_callback = ModelCheckpoint(checkpoint_path,
monitor='val_accuracy',
verbose=1,
save_best_only=True,
save_weights_only=True)
#모델 학습
history = model.fit((q1_data, q2_data), labels, batch_size=BATCH_SIZE,
epochs=NUM_EPOCHS,
validation_split=VALID_SPLIT,
callbacks=[earlystop_callback, cp_callback])
Python
복사
여기서 특별한 점은, 두 개의 문장 벡터를 입력하는 것이기 때문에 모델에 입력하는 값이 두 개라는 점입니다.
( (q1_data, q2_data) ) 모델에 입력하는 값은 튜플로 구성해서 입력합니다.
이제 학습한 모델을 통해 평가데이터를 이용하여 모델을 평가합니다.
def plot_graphs(history, string):
plt.plot(history.history[string])
plt.plot(history.history['val_'+string], '')
plt.xlabel("Epochs")
plt.ylabel(string)
plt.legend([string, 'val_'+string])
plt.show()
plot_graphs(history, 'loss')
Python
복사
CNN 모델 학습에 대한 손실값 그래프

plot_graphs(history, 'accuracy')
Python
복사
CNN 모델 학습에 대한 정확도 그래프
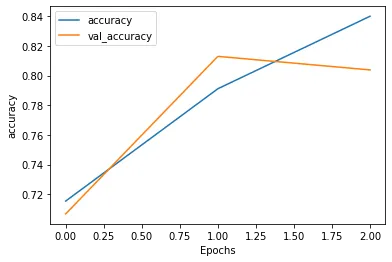
Epoch를 한번 했을 때가 가장 좋은 성능을 낸다는 것을 알 수 있습니다.
Score
캐글에 제출한 결과 CNN 모델의 테스트 성능은 Score 점수 0.57777로 측정되었습니다.
5-4-3. MaLSTM
MaLSTM이란 맨해튼 거리(Manhattan Distance) + LSTM의 줄임말임말로써, 일반적으로 문장의 유사도를 계산할 때 코사인 유사도를 사용하는 대신 맨해튼 거리를 사용하는 모델입니다.
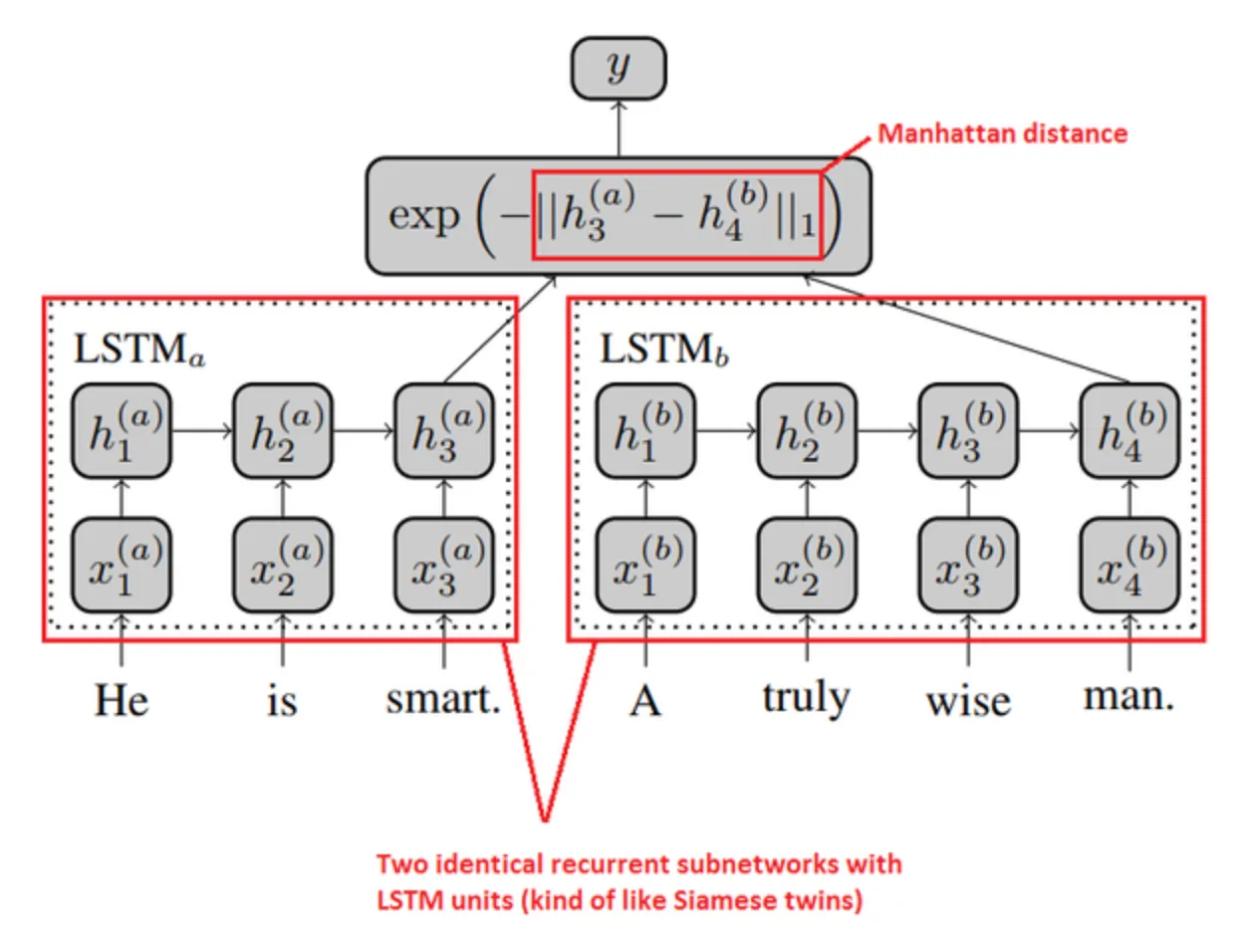
모델 구현
class MaLSTM(tf.keras.Model):
def __init__(self, **kargs):
super(MaLSTM, self).__init__(name=model_name)
self.embedding = layers.Embedding(input_dim=kargs['vocab_size'],
output_dim=kargs['embedding_dimension'])
self.lstm = layers.LSTM(units=kargs['lstm_dimension'])
def call(self, x):
x1, x2 = x
x1 = self.embedding(x1)
x2 = self.embedding(x2)
x1 = self.lstm(x1)
x2 = self.lstm(x2)
x = tf.exp(-tf.reduce_sum(tf.abs(x1 - x2), axis=1))
return x
Python
복사
각 문장을 각 네트워크(임베딩 + LSTM)에 통과시킨 후 최종 출력 벡터 사이의 맨해튼 거리를 측정해 최종 충력값으로 뽑는 구조입니다.
유사도값의 경우 거리가 멀수록 작 아지고, 가까울수록 1에 가까워집니다.
모델 학습을 위한 하이퍼파라미터를 구성합니다.
model_name = 'malstm_similarity'
BATCH_SIZE = 128
NUM_EPOCHS = 5
VALID_SPLIT = 0.1
kargs = {
'vocab_size': prepro_configs['vocab_size'],
'embedding_dimension': 100,
'lstm_dimension': 150,
}
Python
복사
모델을 생성합니다.
model = MaLSTM(**kargs)
model.compile(optimizer=tf.keras.optimizers.Adam(1e-3),
loss=tf.keras.losses.BinaryCrossentropy(),
metrics=[tf.keras.metrics.BinaryAccuracy(name='accuracy')])
Python
복사
모델을 학습시킵니다.
# overfitting을 막기 위한 ealrystop 추가
earlystop_callback = EarlyStopping(monitor='val_accuracy', min_delta=0.0001, patience=1)
# min_delta: the threshold that triggers the termination (acc should at least improve 0.0001)
# patience: no improvment epochs (patience = 1, 1번 이상 상승이 없으면 종료)\
checkpoint_path = DATA_OUT_PATH + model_name + '/weights.h5'
checkpoint_dir = os.path.dirname(checkpoint_path)
# Create path if exists
if os.path.exists(checkpoint_dir):
print("{} -- Folder already exists \n".format(checkpoint_dir))
else:
os.makedirs(checkpoint_dir, exist_ok=True)
print("{} -- Folder create complete \n".format(checkpoint_dir))
cp_callback = ModelCheckpoint(
checkpoint_path, monitor='val_accuracy', verbose=1, save_best_only=True, save_weights_only=True)
#모델 학습
history = model.fit((q1_data, q2_data), labels, batch_size=BATCH_SIZE, epochs=NUM_EPOCHS,
validation_split=VALID_SPLIT, callbacks=[earlystop_callback, cp_callback])
Python
복사
이제 학습한 모델을 통해 평가데이터를 이용하여 모델을 평가합니다.
plot_graphs(history, 'loss')
Python
복사
MaLSTM 모델의 손실함수 그래프

plot_graphs(history, 'accuracy')
Python
복사
MaLSTM 모델의 정확도 함수 그래프

검증데이터에서 보면 3에폭에서 가장 좋은 성능을 보입니다.
이제 가장 좋은 성능을 보이는 파라미터를 사용하여 테스트 데이터에 대해 예측한 뒤 캐글에 제출하겠습니다.
predictions = model.predict((test_q1_data, test_q2_data), batch_size=BATCH_SIZE)
output = pd.DataFrame( data={"test_id":test_id_data, "is_duplicate": list(predictions)} )
output.to_csv(DATA_OUT_PATH+"rnn_predict.csv", index=False, quoting=3)
Python
복사
Score
평가데이터를 통해 캐글에 제출한 결과 0.54의 로그 손실값(log loss) 점수가 나왔습니다
5-5. Conclusion
XGBoot, CNN, MaLSTM 모델을 사용하여 모델을 평가한 결과, CNN이 가장 우수한 점수를 얻었습니다. 다만 LSTM 모델의 경우 층을 깊게 해야 하는데 반해 위에서 사용한 MaLSTM 모델은 공부를 위해 층을 얇게 설정했으므로, 좀 더 깊게 설정하면 더 좋은 성능이 나올 것이라 기대됩니다.
.png&blockId=ecf483d1-76bc-478a-b4bd-145c8d6cd912)
실습문제 및 과제 COLAB 노트
노트 파일의 이름은 꼭 다음 양식을 지켜주세요.
주차_이름_레벨
ex) 1주차_나마로_LEVEL2